Journal
Scalable Chain of Thoughts via Elastic Reasoning

Summary
Salesforce AI Research developed ‘Elastic Reasoning,’ a framework that enables Large Reasoning Models (LRMs) to operate effectively under strict output length constraints. It achieves this by separating reasoning output into independent ‘thinking’ and ‘solution’ budgets and employing a budget-constrained reinforcement learning strategy. This approach led to over 30% reduction in token usage, improved performance on math and programming benchmarks (e.g., 35.0% accuracy on AIME2024), and significantly lower training costs compared to existing methods, making reasoning models more practical for real-world deployment.
Salesforce AI Research 推出了“Elastic Reasoning”(弹性推理)框架,旨在让大型推理模型在严格的输出长度限制下仍能有效运作。该框架通过将推理输出划分为独立的“思考”和“解答”预算,并采用预算约束强化学习策略来实现这一点。与现有方法相比,这种方法不仅将 Token 使用量减少了 30% 以上,显著降低了训练成本,还提升了数学和编程基准测试的表现(例如在 AIME2024 上达到了 35.0% 的准确率),从而大大提高了推理模型在现实场景中部署的实用性。
注释
- Large Reasoning Models (LRMs):译为“大型推理模型”,指专门设计用于执行复杂推理任务的大规模语言模型。
- Budget:在计算机科学和 AI 语境中,通常指代某种资源的配额或限制。此处译为“预算”,指代 Token(词元)的分配额度。
- Token:译文中保留英文或称为“词元”。在大模型中,它是文本处理的基本单位。此处“Token 使用量”指模型生成或处理文本的长度/消耗。
- AIME2024:全称为 American Invitational Mathematics Examination(美国数学邀请赛),是极具挑战性的高中数学竞赛,常被用作测试高级推理能力的基准。
Overview
Elastic Reasoning addresses a critical bottleneck in deploying Large Reasoning Models (LRMs) that use Chain-of-Thought (CoT) prompting: their tendency to generate excessively long outputs that consume significant computational resources and increase inference costs. While CoT has revolutionized LLM performance on complex tasks like mathematics and programming by enabling step-by-step reasoning, the uncontrolled length of these reasoning chains creates practical deployment challenges in resource-constrained environments.
弹性推理解决了采用“思维链”提示的大型推理模型在部署过程中面临的一个关键瓶颈:这些模型倾向于生成过长的输出,导致大量计算资源消耗和推理成本增加。尽管思维链通过实现逐步推理,彻底改变了大型语言模型在数学和编程等复杂任务上的表现,但这些推理链长度不可控的问题,在资源受限的环境中构成了实际部署的挑战。
注释
- Chain-of-Thought (CoT) prompting:译为“思维链提示”或“思维链提示技术”。这是一种通过引导模型一步步展示推理过程来提高复杂问题解决能力的提示策略。
- Inference costs:译为“推理成本”。指模型在部署后进行预测和生成内容时所产生的计算费用,通常区别于“训练成本”。
- Resource-constrained environments:译为“资源受限环境”。指计算能力、内存或电力有限的硬件或运行环境。
The research introduces a framework that enables LRMs to maintain their reasoning capabilities while operating under strict inference-time budget constraints. The approach fundamentally reconceptualizes how reasoning models allocate their computational resources during inference, separating the reasoning process into distinct phases with independent budget allocations.
这项研究提出了一种框架,使大型推理模型(LRMs)能够在严格的推理时预算约束下运行,同时保持其推理能力。该方法从根本上重新构想了推理模型在推理期间分配计算资源的方式,将推理过程划分为不同阶段,并为每个阶段分配独立的预算。
Problem Context and Motivation
Current Chain-of-Thought models face a fundamental deployment paradox: their reasoning capabilities rely on generating lengthy intermediate steps, but these extended outputs create prohibitive costs and latency issues for real-world applications. Existing length control methods fall into two categories, each with significant limitations.
General text generation length control methods, such as manipulating positional encodings or modifying training objectives, work well for tasks like summarization but fail to preserve the structured nature of reasoning processes. These approaches treat reasoning chains as regular text, potentially disrupting the logical flow essential for correct problem-solving.
Reasoning-specific length control methods, including approaches like Budget Forcing (S1) and L1, attempt to address the structured nature of reasoning but suffer from critical flaws. Budget Forcing simply truncates outputs when token limits are reached, often cutting off the final solution and rendering the entire output useless. L1 uses reinforcement learning for dynamic allocation but requires expensive training and still shows performance degradation under constraints.
The core issue with existing methods is their failure to recognize that reasoning outputs have two functionally distinct components: the intermediate thinking process and the final solution. Naive truncation frequently eliminates the solution entirely, while current training approaches don’t adequately prepare models for the reality of truncated reasoning during deployment.
当前的思维链模型面临一个根本性的部署悖论:它们的推理能力依赖于生成冗长的中间步骤,但这些长篇输出却给现实应用带来了高昂的成本和延迟问题。现有的长度控制方法分为两类,各自都存在显著的局限性。
通用文本生成长度控制方法(如操纵位置编码或修改训练目标)在摘要生成等任务上表现出色,却无法保留推理过程的结构化特征。这些方法将推理链视为普通文本,可能会破坏正确解决问题所必需的逻辑连贯性。
专用于推理的长度控制方法(如 Budget Forcing (S1) 和 L1)试图应对推理的结构化特征,但存在致命缺陷。Budget Forcing 仅在达到 Token 限制时截断输出,这往往会导致最终解答被截断,致使整段输出失去价值。L1 虽然利用强化学习进行动态分配,但不仅训练成本高昂,而且在约束条件下仍会出现性能下降。
现有方法的核心问题在于未能认识到:推理输出包含两个功能本质截然不同的组成部分——中间思维过程和最终解答。简单的截断操作往往会完全丢失解答部分,而当前的训练方法也未能让模型为部署过程中推理可能被截断的现实情况做好充分准备。
注释
- Positional encodings:译为“位置编码”。一种让 Transformer 模型理解输入序列中词语顺序的技术。
- Budget Forcing (S1):保留原文或译为“预算强制”。指一种强制模型在特定预算(长度)内生成输出的方法,S1 可能是相关的论文或模型代号。
- L1:保留原文。此处指代某种特定的模型或方法名称(通常与 L1 正则化无关,可能是特定研究中的代号)。
- Performance degradation:译为“性能下降”。指模型在特定条件(如严格限制)下表现变差。
Methodology
Elastic Reasoning introduces two complementary innovations: Separate Budgeting for Inference and Budget-Constrained Rollout for Training.
弹性推理引入了两项互补的创新:推理分离式预算(Separate Budgeting for Inference)和预算受限的展开训练(Budget-Constrained Rollout for Training)。
术语说明
- Complementary:译为“互补的”或“相辅相成的”。指这两项创新机制相互配合,共同解决推理效率问题。
- Separate Budgeting for Inference:译为“推理分离式预算”或“推理的分离式预算”。指在推理(Inference)阶段,将计算预算(如 token 数量)进行独立分配,可能指分别为“思维过程”和“最终答案”分配不同的资源配额。
- Budget-Constrained Rollout for Training:译为“预算受限的展开训练”。“Rollout”(展开)是强化学习中的术语,指模型根据当前策略生成一系列动作或序列的过程。这里指在训练过程中,强制模型在有限的预算内进行序列生成与尝试,从而训练其适应资源限制。
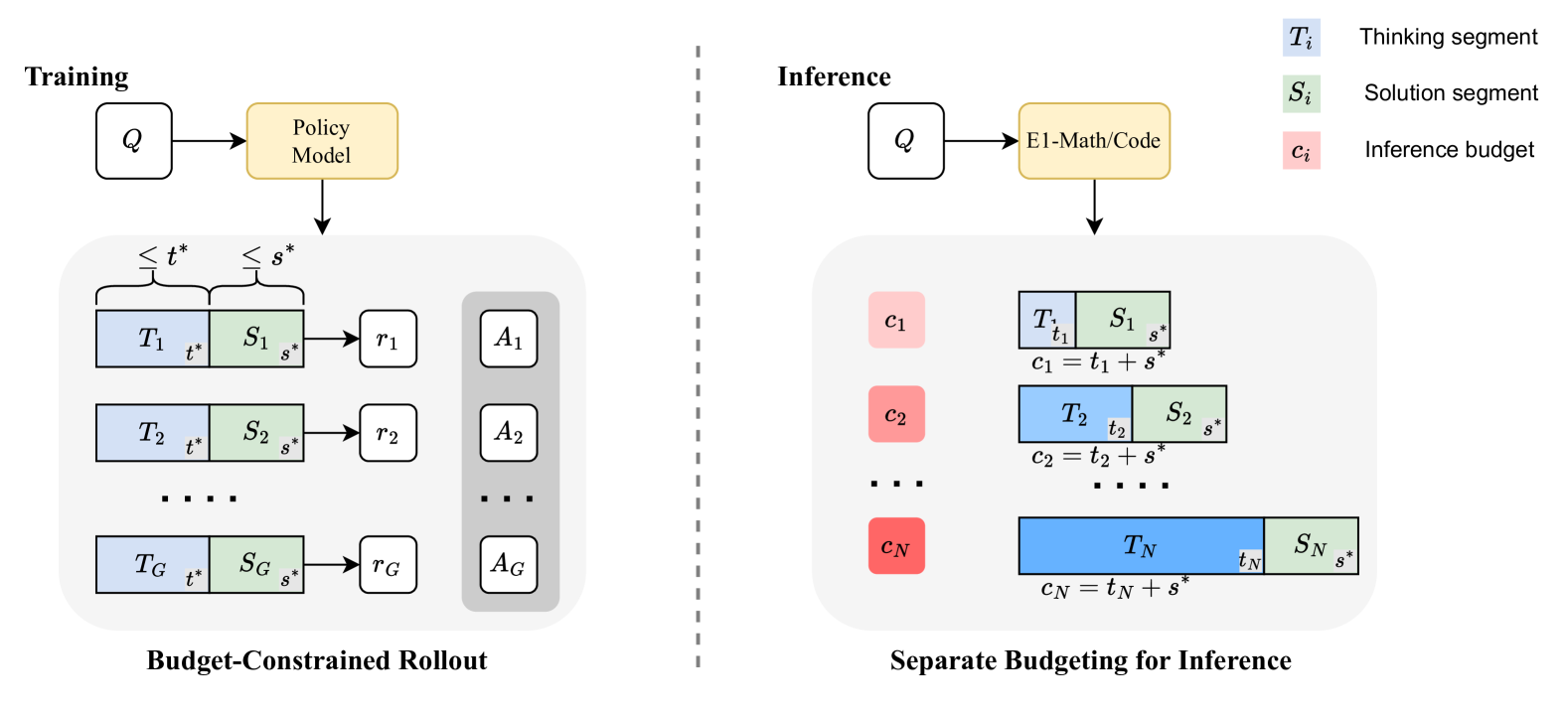
Separate Budgeting for Inference
The inference mechanism explicitly divides the total computational budget into two independent allocations. Given a total inference budget , the framework allocates tokens for the thinking phase and tokens for the solution phase, where .
During generation, the model begins producing content within designated thinking markers (<think> and </think>). If the model naturally concludes its reasoning by emitting before exhausting the -token budget, it immediately transitions to generating the final solution. However, if the thinking budget is exhausted before natural conclusion, the framework forcibly appends </think> to terminate the reasoning phase.
This mechanism guarantees that the solution component receives its dedicated budget allocation, preventing the common failure mode where truncation eliminates the final answer entirely. The thinking budget can be dynamically adjusted at inference time to accommodate different application requirements without requiring model retraining.
该推理机制明确地将总计算预算划分为两个独立的部分。在给定总推理预算 的情况下,框架为思考阶段(thinking phase)分配 个 token,为解答阶段(solution phase)分配 个 token,即满足
在生成过程中,模型首先在指定的思考标记(<think> 和 </think>)内产出内容。若模型在耗尽 个 token 的预算前,通过输出 </think> 自然地结束了推理过程,它将立即过渡到最终解答的生成。然而,如果思考预算在推理自然结束前就已耗尽,框架则会强制附加 </think> 标记以终止推理阶段。
这种机制确保了解答部分拥有专属的预算配额,从而避免了常见的因截断而导致最终答案完全丢失的失效模式。思考预算可以在推理时根据不同的应用需求进行动态调整,而无需重新训练模型。
注释
- Inference (推理):在机器学习语境下,指模型在训练完成后,实际处理输入并生成输出的过程。
- Token (令牌/标记):文本处理的最小单位。在翻译中通常保留原词,或根据语境译为“字符单位”。
- Rollout (展开/采样):强化学习中的术语,指模型根据当前策略生成一系列动作或序列的过程。此处译为“展开”以符合中文技术文档习惯。
- Failure mode (失效模式):工程学术语,指系统可能出现故障的具体方式。
Budget-Constrained Rollout for Training 训练阶段的预算约束展开
While Separate Budgeting handles inference-time allocation, models still require training to reason effectively under truncated conditions. The training component uses reinforcement learning with Generalized Policy Optimization (GRPO) to teach models adaptive reasoning under budget constraints.
During training, the framework simulates the inference-time budgeting process. The model generates responses subject to budget constraints tokens. The thinking segment is generated up to the limit, with forced termination if necessary, followed by solution generation within the budget. The training process optimizes the model’s policy to maximize task-specific rewards while operating under these constraints:
where represents the task-specific reward function evaluating solution quality.
A key insight from the training approach is that models trained with a fixed, relatively modest budget generalize remarkably well to diverse budget configurations at test time. This eliminates the need for extensive retraining across different deployment scenarios.
虽然“独立预算机制”(Separate Budgeting)负责处理推理阶段的资源分配,但模型仍需通过训练,以便在截断条件下进行有效的推理。训练组件采用结合了广义策略优化(GRPO)的强化学习算法,旨在教导模型在预算约束下进行自适应推理。
在训练过程中,该框架模拟推理时的预算分配流程。模型在预算约束 个 Token 的限制下生成响应。思考片段(Thinking segment)的生成长度受限于 ,必要时会强制终止,随后在 的预算范围内生成解法。
训练过程在这些约束条件下优化模型策略 ,以最大化特定任务的奖励:
其中 代表用于评估解法质量的特定任务奖励函数。
该训练方法的一个核心洞见是:在固定且相对适度的预算下训练出的模型,在测试阶段面对各种预算配置时,表现出了卓越的泛化能力。这也就免除了针对不同部署场景进行大规模重新训练的必要。
【术语与翻译注释】
- Budget-Constrained Rollout:译为“预算约束展开”。在强化学习语境中,“Rollout”指模拟一条轨迹或生成序列的过程,此处译为“展开”或“推演”均符合学术规范。
- Separate Budgeting:译为“独立预算机制”。指将思考阶段和生成阶段的预算分开处理的策略。
- Tokens:译文中保留了“Token”,也可译为“词元”。在 LLM 领域,“Token”是更通用的计量单位。
- GRPO (Generalized Policy Optimization):广义策略优化,一种强化学习算法。
- Generalize:译为“泛化”,指模型在未见过的新环境(这里是新的预算配置)下仍能表现良好的能力。
- Thinking segment:译为“思考片段”,特指思维链(Chain of Thought)等内部推理过程生成的部分。
Results and Performance 实验结果与性能
The empirical evaluation demonstrates Elastic Reasoning’s effectiveness across mathematical and programming domains using two specialized models: E1-Math-1.5B (based on DeepScaleR-1.5B-Preview) and E1-Code-14B (based on DeepCoder-14B-Preview).
实验评估通过两个专用模型——E1-Math-1.5B(基于 DeepScaleR-1.5B-Preview)和 E1-Code-14B(基于 DeepCoder-14B-Preview)——验证了弹性推理在数学和编程领域的有效性。
Performance Under Budget Constraints 预算约束下的性能表现
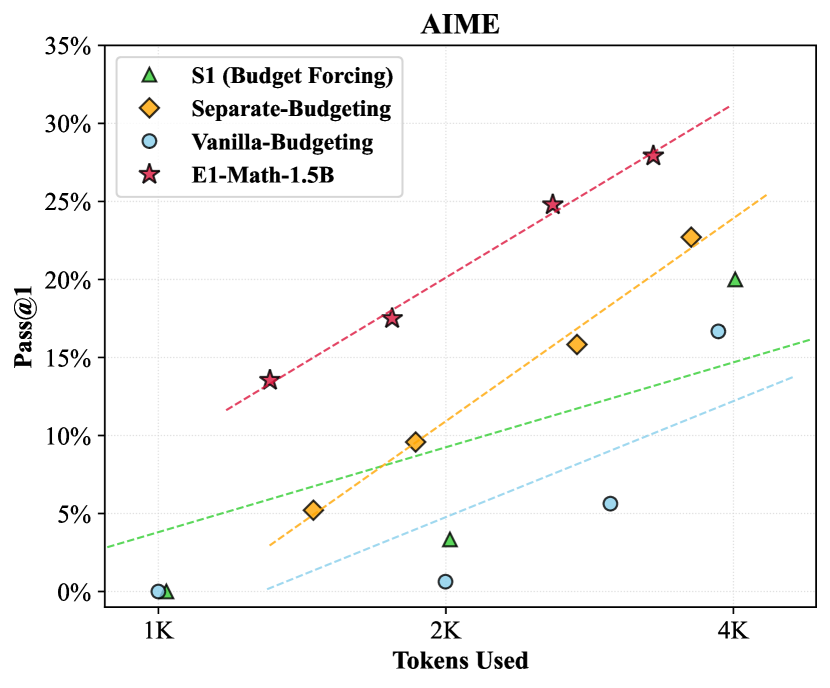
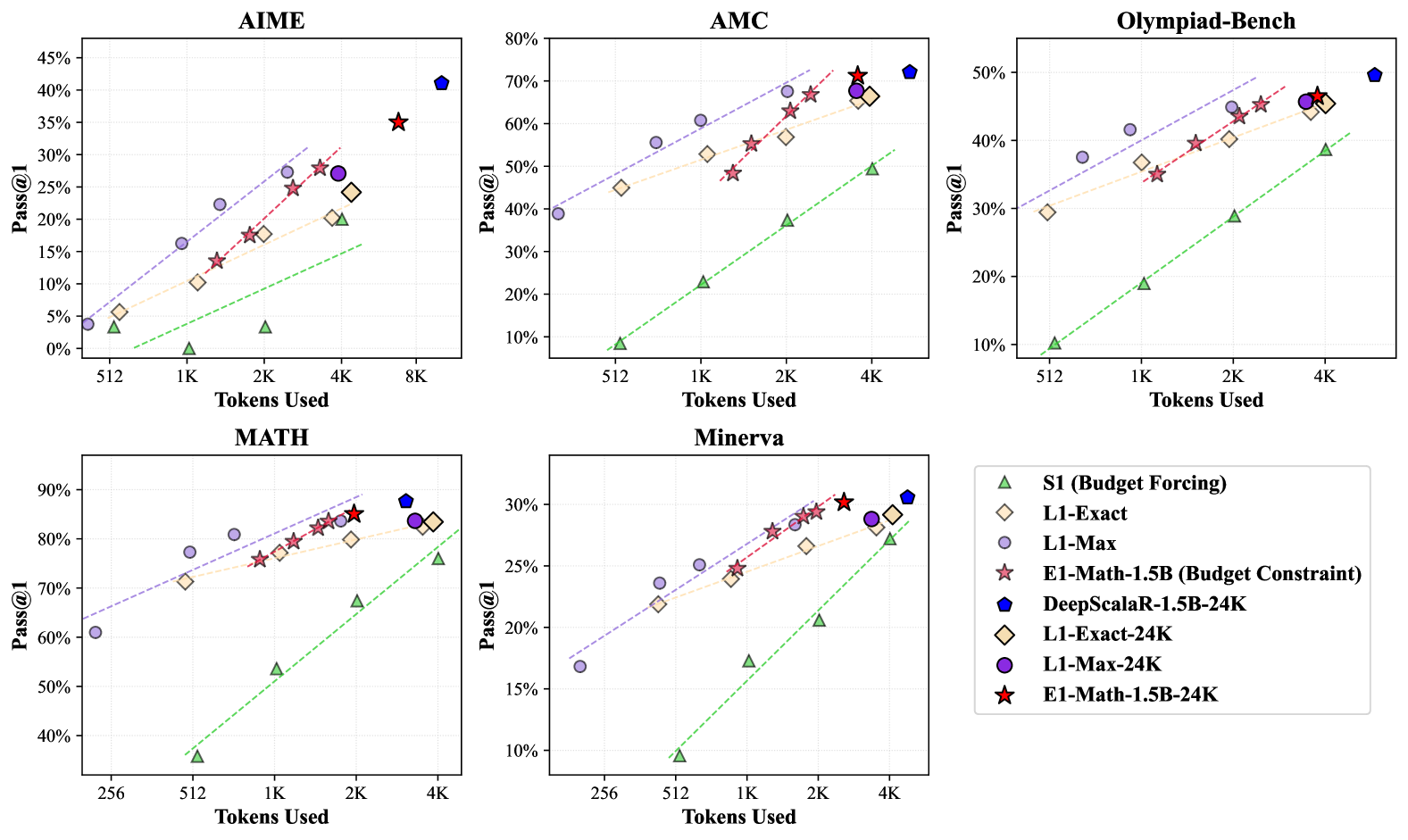
On mathematical reasoning benchmarks, E1-Math-1.5B consistently outperforms existing length control methods. On the challenging AIME2024 dataset, it achieves 35.0% accuracy compared to L1-Max’s 27.1% and L1-Exact’s 24.2%. The performance advantage is maintained across various budget constraints, demonstrating the framework’s robustness.
在数学推理基准测试中,E1-Math-1.5B 始终优于现有的长度控制方法。在高难度的 AIME2024 数据集上,其准确率达到 35.0%,相比之下 L1-Max 为 27.1%,L1-Exact 为 24.2%。这种性能优势在各种预算约束下均得以保持,体现了该框架的鲁棒性。
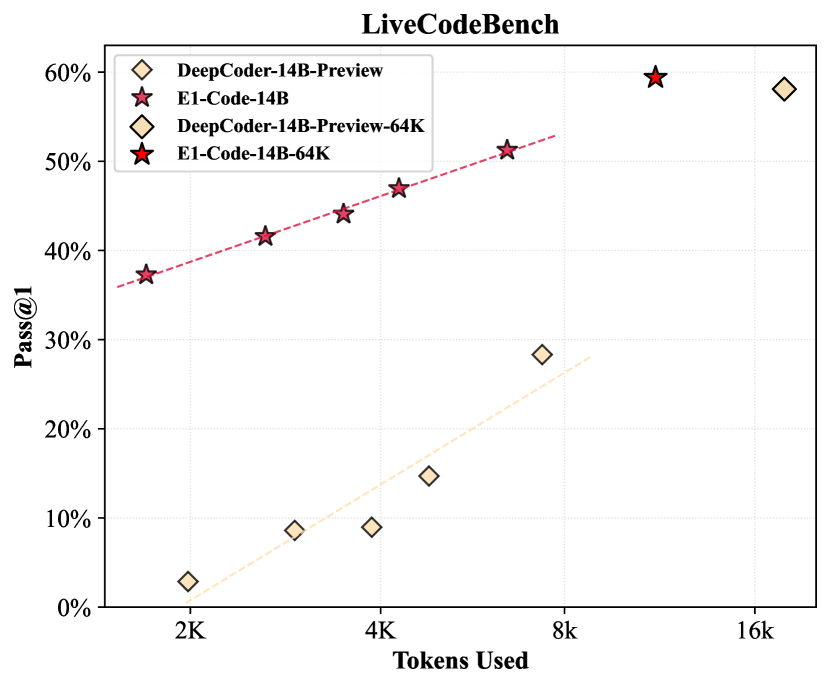
For programming tasks, E1-Code-14B shows remarkable scalability. While the base DeepCoder-14B-Preview model fails catastrophically under tight constraints (achieving less than 10% accuracy with budgets under 4K tokens), E1-Code-14B maintains steady performance improvement as budget increases. On Codeforces, E1-Code-14B achieves a rating of 1987 (96.0 percentile), demonstrating competitive performance with state-of-the-art models.
在编程任务方面,E1-Code-14B 展现出卓越的可扩展性。尽管 DeepCoder-14B-Preview 基础模型在严格约束下会严重失效(预算低于 4K 词元时准确率不足 10%),但随着预算的增加,E1-Code-14B 保持了性能的稳步提升。在 Codeforces 平台上,E1-Code-14B 获得了 1987 的评分(位列 96.0 百分位),显示出与最先进模型(SOTA)相媲美的竞争力。
术语说明
- Benchmark:译为“基准”或“基准测试”。用于评估模型性能的标准测试集。
- Catastrophically:译为“灾难性地”或“严重”。在此语境下指模型在极端限制下表现极差,几乎失去可用性。
- Robustness:译为“鲁棒性”。指系统在异常或危险情况下生存的能力,在 AI 领域常指模型在面对不同输入或干扰时保持性能稳定的能力。
- State-of-the-art (SOTA):译为“最先进的”或“当前最佳的”。指在特定任务上目前性能最高的技术水平。
Efficiency and Conciseness 效率与精简
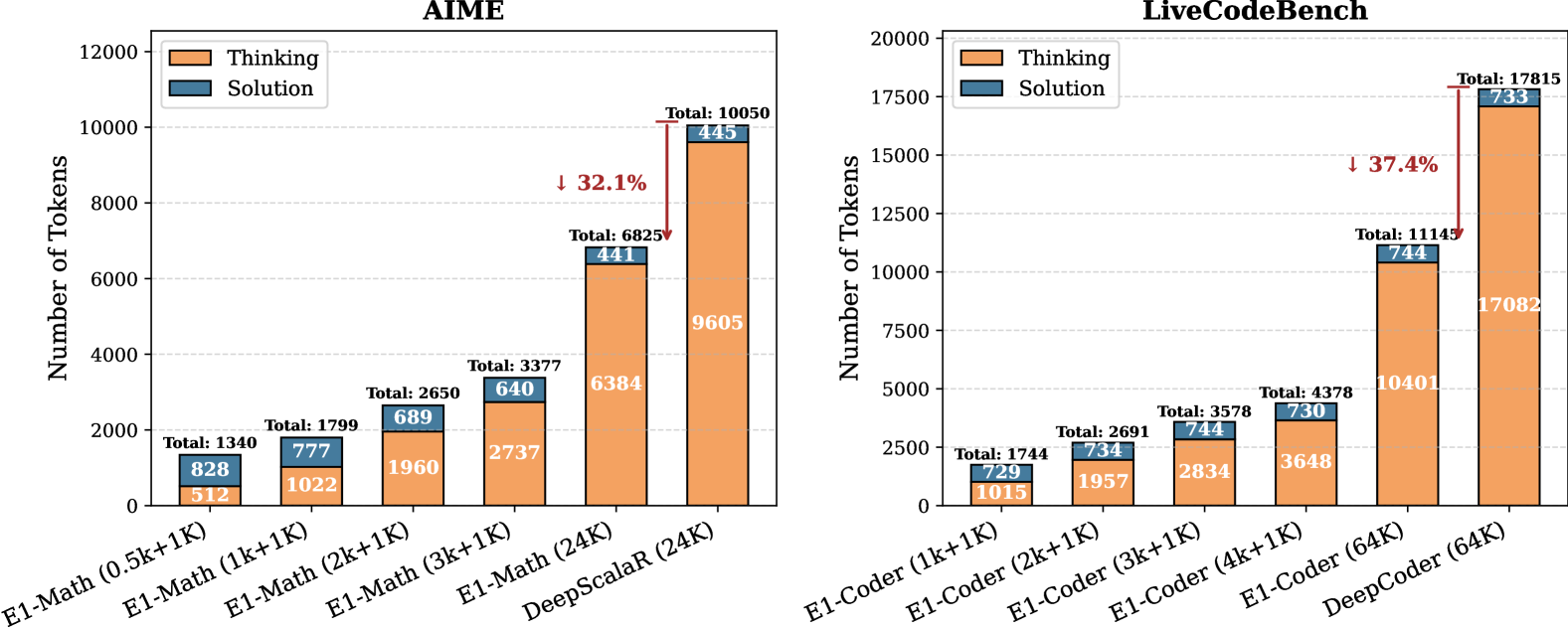
A particularly striking finding is that Elastic Reasoning models generate significantly shorter outputs than their base models, even in unconstrained settings. E1-Math-1.5B reduces average token usage by over 30% across datasets, while E1-Code-14B reduces usage by 37.4% on LiveCodeBench (from 17,815 to 11,145 tokens).
一个尤为引人注目的发现是,即使在无约束环境下,弹性推理模型生成的输出也明显短于其基础模型。在各个数据集上,E1-Math-1.5B 将平均词元使用量减少了 30% 以上;而在 LiveCodeBench 上,E1-Code-14B 将使用量减少了 37.4%(从 17,815 降至 11,145 个词元)。一个尤为引人注目的发现是,即使在无约束环境下,弹性推理模型生成的输出也明显短于其基础模型。在各个数据集上,E1-Math-1.5B 将平均词元使用量减少了 30% 以上;而在 LiveCodeBench 上,E1-Code-14B 将使用量减少了 37.4%(从 17,815 降至 11,145 个词元)。
This reduction occurs while maintaining or slightly improving performance, suggesting that the training process encourages more focused and efficient reasoning rather than simply enforcing arbitrary length limits.
在保持甚至略微提升性能的同时实现了这一缩减,这表明训练过程促使模型进行更加专注且高效的推理,而非仅仅是强制施加任意的长度限制。
术语说明
- Unconstrained settings:译为“无约束环境”或“不受限制的场景”。指在推理阶段不对模型的输出长度做强制截断或限制的测试条件。这一发现的重要性在于证明了模型将“高效”内化为一种能力,而不仅仅是对限制条件的被动反应。
- Arbitrary length limits:译为“任意的长度限制”。指外部强制设定的、缺乏针对性的长度上限(如简单截断)。原文强调模型的简洁性是习得的,而非被迫的。
Generalization and Training Efficiency 泛化与训练效率
Models trained with fixed budget constraints demonstrate strong generalization to unseen budget configurations at test time. The framework achieves competitive performance across diverse evaluation scenarios without requiring additional fine-tuning for each specific budget constraint.
在固定预算约束下训练的模型,在测试时面对未见过的预算配置,展现出了强大的泛化能力。该框架在多样化的评估场景中均能取得具有竞争力的性能表现,且无需针对每种特定的预算约束进行额外的微调。
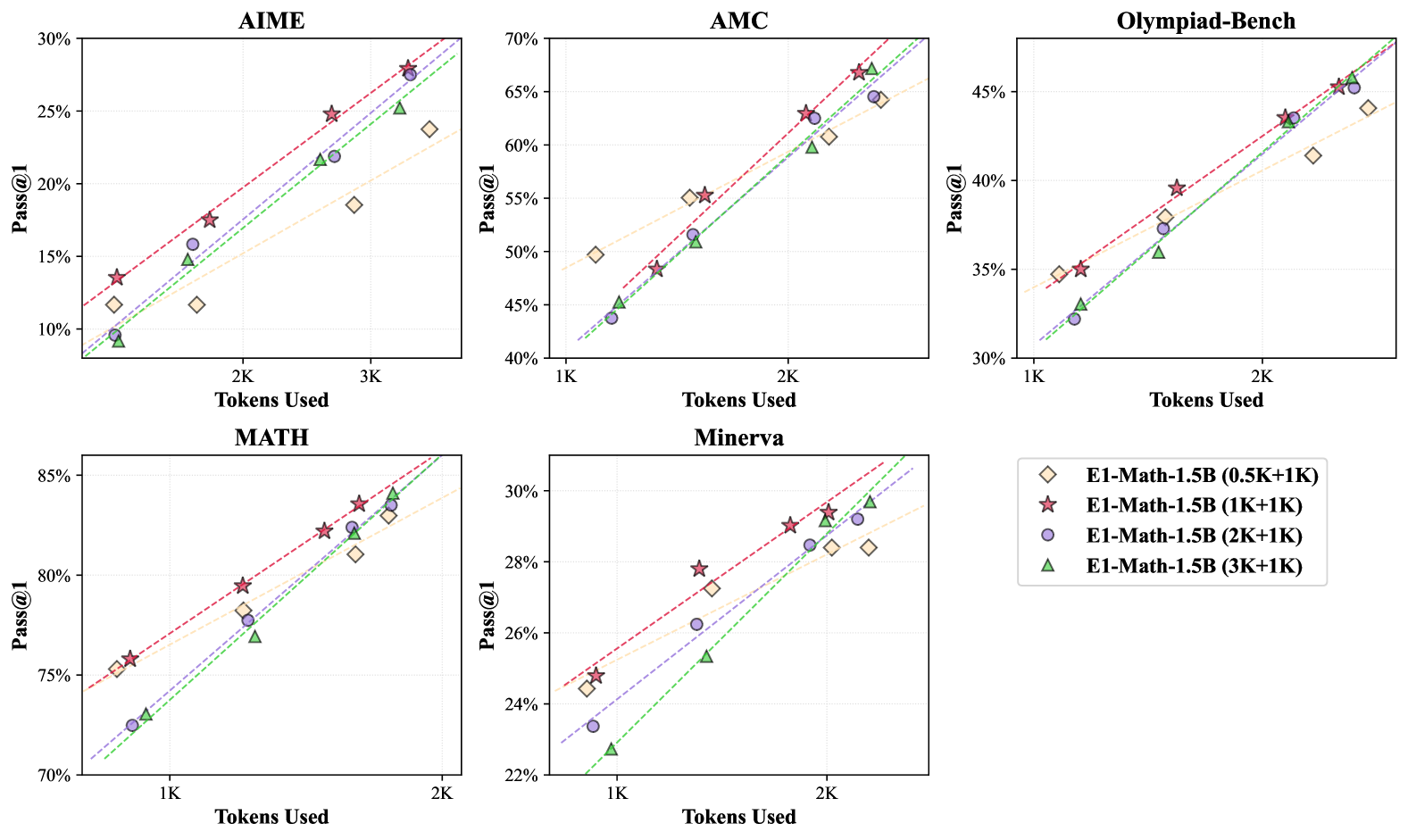
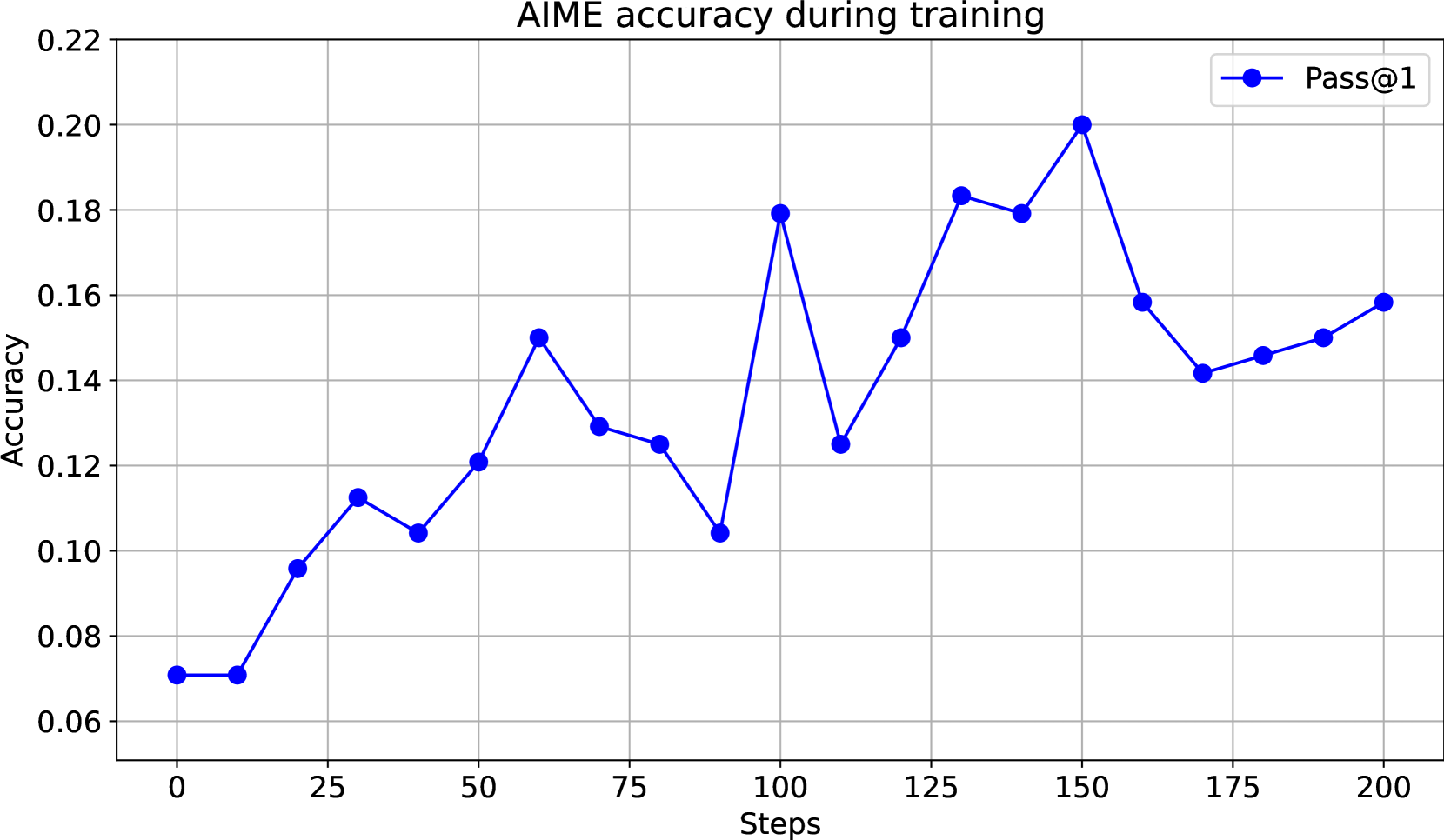
Additionally, the training process requires significantly fewer computational resources compared to baseline methods. E1-Math-1.5B requires only 200 training steps compared to 700 steps for L1-Exact and 820 for L1-Max, representing substantial cost savings.
此外,与基线方法相比,该训练过程所需的计算资源显著更少。E1-Math-1.5B 仅需 200 个训练步,而 L1-Exact 和 L1-Max 分别需要 700 步和 820 步,这意味着成本的大幅节约。
术语说明
- Unseen budget configurations:译为“未见过的预算配置”或“未知预算配置”。指在模型训练阶段未曾遇到过的、在测试时新设定的预算限制条件,这是衡量模型泛化能力的重要指标。
- Fine-tuning:译为“微调”。指在预训练模型的基础上,使用特定数据集进行进一步的训练,以适应特定任务。
- Baseline methods:译为“基线方法”或“基准方法”。指用于作为对比参考的标准方法或模型,用于评估新方法的有效性。
- Training steps:译为“训练步数”。指模型在训练过程中处理数据批次(batches)的迭代次数,是衡量训练成本和效率的重要指标。
Technical Innovation and Significance 技术创新与意义
Elastic Reasoning’s primary innovation lies in recognizing and addressing the structural properties of reasoning outputs rather than treating them as undifferentiated text. By explicitly separating thinking and solution phases, the framework preserves the functional integrity of reasoning processes under resource constraints.
The budget-constrained rollout training strategy represents a novel application of reinforcement learning to instill specific behavioral properties (budget-awareness and conciseness) in language models. Unlike previous approaches that simply penalize length or force early termination, this method teaches models to reason adaptively when their thought processes are truncated.
The framework’s ability to improve efficiency even in unconstrained settings suggests that the training process encourages fundamental improvements in reasoning quality rather than mere compression. This indicates a deeper optimization of the reasoning process itself, prioritizing informative content and eliminating redundancy.
弹性推理的主要创新在于识别并应对推理输出的结构属性,而非将其视为无差别的文本。通过显式分离思维与解题两个阶段,该框架在资源约束下维护了推理过程的功能完整性。
预算受限的展开训练策略代表了强化学习的一种新颖应用,旨在向语言模型赋予特定的行为属性(即预算感知和简洁性)。与以往仅仅惩罚长度或强制早期终止的方法不同,该方法教导模型在其思维过程受到截断时进行自适应推理。
该框架即使在无约束环境下也能提升效率,这一事实表明训练过程促进了推理质量的根本性提升,而不仅仅是单纯的数据压缩。这表明对推理过程本身进行了更深层次的优化,即优先保留富含信息的内容并消除冗余。
术语说明
- Undifferentiated text:译为“无差别文本”或“未分化文本”。指将一大段文本视为均质的字符串,不区分哪部分是思考过程,哪部分是最终答案。这里强调 Elastic Reasoning 识别了输出内部的结构(思考 vs 答案)。
- Functional integrity:译为“功能完整性”。指推理的各个部分(如思考步骤、推导逻辑、最终结论)在受限情况下依然能正常发挥其应有的作用,并没有因为长度限制而导致逻辑崩坏或错误。
- Rollout training strategy:译为“展开训练策略”。在强化学习(特别是涉及序列生成的任务)中,Rollout 指的是模型根据当前策略生成完整序列(轨迹)的过程。这里指在训练过程中模拟生成完整的推理路径。
- Budget-awareness:译为“预算感知”。指模型能够“感知”到当前的资源限制(如剩余 token 数量),并据此调整其生成策略。
- Reason adaptively:译为“自适应推理”。指模型能够根据当前情况(如即将达到长度限制)动态调整推理深度或表达方式,而不是机械地被切断。
Implications and Future Directions 启示与未来方向
Elastic Reasoning directly addresses the practical deployment gap between powerful reasoning models and real-world resource constraints. By enabling reliable performance under strict budget limits while reducing overall computational requirements, the framework makes advanced reasoning capabilities accessible to a broader range of applications and deployment scenarios.
The approach opens several promising research directions. The framework’s current focus on clearly separated thinking and solution phases may require extension for tasks with more complex reasoning structures, such as multi-step interactive problem-solving or iterative refinement processes.
Additionally, while the framework ensures solution completeness, questions remain about the interpretability and trustworthiness of reasoning when intermediate steps are truncated. Future work should explore methods for maintaining reasoning transparency and developing guidelines for safe deployment in high-stakes applications where justification completeness is critical.
The demonstrated generalization capabilities suggest potential for developing unified models that can dynamically adapt to varying computational budgets across diverse deployment contexts, representing a significant step toward more flexible and practical AI systems.
弹性推理直接应对了强大的推理模型与现实世界资源约束之间存在的实际部署鸿沟。该框架既能在严格的预算限制下实现可靠性能,又能降低整体计算需求,从而使先进的推理能力能够应用于更广泛的应用和部署场景。
该方法开辟了若干充满前景的研究方向。该框架目前侧重于清晰分离“思维”与“解题”两个阶段,对于具有更复杂推理结构的任务(如多步交互式问题求解或迭代优化过程),这一侧重点可能需要进一步扩展。
此外,尽管该框架确保了解题结果的完整性,但在中间步骤被截断的情况下,关于推理的可解释性和可信度仍存疑虑。未来的研究应探索保持推理透明度的方法,并制定在高风险应用中安全部署的准则,因为在这些应用场景中,论证的完整性至关重要。
已证实的泛化能力显示出开发统一模型的潜力,这类模型能够在多样化的部署环境中动态适应不同的计算预算,这代表了向构建更灵活、更实用的 AI 系统迈出的重要一步。
Relevant Citations
L1: Controlling how long a reasoning model thinks with reinforcement learning This paper presents a direct and highly relevant competing method to Elastic Reasoning. L1 also uses a reinforcement learning framework to manage generation length, making it a key baseline against which the presented work’s performance, efficiency, and training costs are compared throughout the experiments. Pranjal Aggarwal and Sean Welleck. L1: Controlling how long a reasoning model thinks with reinforcement learning. URL2025.
s1: Simple test-time scaling The S1 method, referred to as ‘budget forcing’ in the paper, is another primary baseline used for comparison. The core idea of Elastic Reasoning, particularly ‘Separate Budgeting’, is presented as a superior alternative to S1’s simpler truncation strategy, highlighting its ability to preserve the crucial solution part of the generation. Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025. URLhttps://arxiv.org/abs/2501.19393.
Deepscaler: Surpassing O1-preview with a 1.5 b model by scal-ing reinforcement learning This paper introduces DeepScaleR, the base model used for the mathematical reasoning experiments in the main paper. DeepScaleR exemplifies the powerful but inefficient reasoning models with uncontrolled output lengths that Elastic Reasoning is designed to address, making it a perfect use-case and starting point for demonstrating the effectiveness of the proposed method. Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, et al.Deepscaler: Surpassing O1-preview with a 1.5 b model by scal-ing reinforcement learning, 2025.URLhttps://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2. Notion blog post.
Chain-of-thought prompting elicits reasoning in large language models This is the foundational paper that introduced Chain-of-Thought (CoT) prompting. The entire problem domain of the main paper—managing the length, cost, and efficiency of extended reasoning trajectories—is built upon the CoT paradigm established by this work, making it a critical and fundamental citation. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URLhttps://arxiv.org/abs/2201.11903.