Journal
s1: Simple test-time scaling

Summary
Researchers at Stanford, UW, and AI2 developed s1-32B, an open-source model that achieves state-of-the-art reasoning performance and clear test-time scaling on challenging benchmarks by fine-tuning on only 1,000 high-quality reasoning samples and employing a simple ‘budget forcing’ inference technique.
斯坦福大学、华盛顿大学 (UW) 和艾伦人工智能研究所 (AI2) 的研究人员开发了 s1-32B 开源模型。该模型仅通过对 1,000 个高质量推理样本进行微调,并采用一种简单的“预算强制”推理技术,便在极具挑战性的基准测试中实现了最先进的推理性能,并展现出了清晰的测试时扩展效果。
注释
-
机构缩写:
-
UW:指华盛顿大学 (University of Washington)。
-
AI2:指艾伦人工智能研究所 (Allen Institute for Artificial Intelligence)。
-
-
专业术语:
-
State-of-the-art:直译为“最先进的”,在 AI 领域常指当前顶尖水平(SOTA)。
-
Test-time scaling:测试时扩展/测试时算力扩展。指在推理阶段通过增加计算资源(如让模型“多想一会儿”)来提升模型性能的能力。
-
Budget forcing:预算强制。这是该研究中提出的一种特定推理技术,指强制模型在预定的计算预算(例如思考步数)内完成推理,而不是在模型认为完成时就停止。
-
Overview
This research tackles a fundamental challenge in artificial intelligence: how to improve the reasoning capabilities of large language models (LLMs) without requiring massive computational resources. While companies like OpenAI have demonstrated impressive test-time scaling with their o1 model—where performance increases as more compute is allocated during inference—the underlying methods have remained proprietary. This work introduces a “simple” approach to replicating these capabilities using just 1,000 carefully curated training examples and a straightforward inference technique called “budget forcing.”
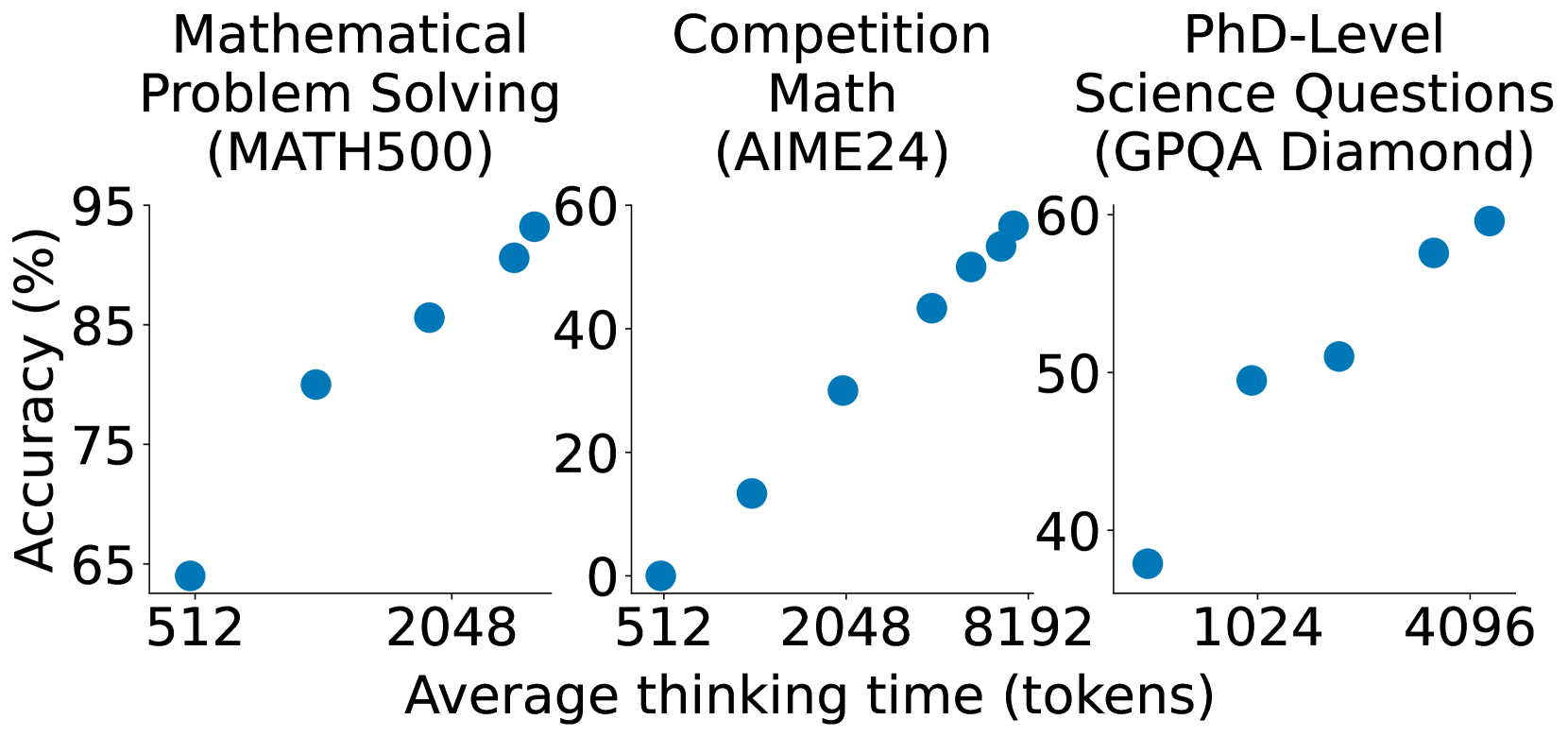 Figure 1: The s1 model demonstrates clear test-time scaling behavior across three challenging benchmarks: MATH500 (mathematical problem solving), AIME24 (competition math), and GPQA Diamond (PhD-level science questions). Performance consistently improves as more thinking tokens are allocated during inference. s1 模型在三项极具挑战性的基准测试中展现了清晰的测试时扩展行为,分别是:MATH500(数学问题求解)、AIME24(竞赛数学)和 GPQA Diamond(博士级科学问题)。随着推理过程中分配的“思考令牌”越来越多,模型的性能也在持续提升。
Figure 1: The s1 model demonstrates clear test-time scaling behavior across three challenging benchmarks: MATH500 (mathematical problem solving), AIME24 (competition math), and GPQA Diamond (PhD-level science questions). Performance consistently improves as more thinking tokens are allocated during inference. s1 模型在三项极具挑战性的基准测试中展现了清晰的测试时扩展行为,分别是:MATH500(数学问题求解)、AIME24(竞赛数学)和 GPQA Diamond(博士级科学问题)。随着推理过程中分配的“思考令牌”越来越多,模型的性能也在持续提升。
注释
-
基准测试:
-
MATH500:用于评估大语言模型解决高中竞赛水平数学问题能力的基准数据集。
-
AIME24:美国邀请数学考试 2024 年的题目,属于高难度的竞赛数学。
-
GPQA Diamond:一个由生物学、物理学和化学领域的专家生成的极难科学问题数据集,通常用于测试模型是否达到专家(博士)水平。
-
-
Thinking tokens (思考令牌):指模型在生成最终答案之前,为了进行推理、规划或验证而产生的中间过程文本所对应的 token。在这里,增加“思考令牌”意味着允许模型花费更多计算资源来“思考”,从而提高准确率。
The Problem: Democratizing Advanced Reasoning 高级推理的民主化
The AI research landscape has been increasingly dominated by closed-source models that achieve state-of-the-art performance through proprietary methods. OpenAI’s o1 model exemplified this trend, showing remarkable reasoning capabilities and test-time scaling properties while keeping its training data and methods secret. Although several research groups attempted to replicate these capabilities using techniques like Monte Carlo Tree Search or reinforcement learning with millions of samples, none had successfully reproduced clear test-time scaling behavior in an open, accessible manner.
This work addresses the gap by pursuing the “simplest approach” to achieve both strong reasoning performance and test-time scaling. The authors demonstrate that competitive results can be achieved with minimal resources: just 1,000 training examples and 26 minutes of fine-tuning on 16 H100 GPUs.
AI 研究的格局正日益受到闭源模型的支配,这些模型利用专有方法实现了最先进的性能。OpenAI 的 o1 模型便是这一趋势的典型例证,它在展现出卓越的推理能力和测试时扩展特性的同时,对其训练数据和方法严格保密。尽管多个研究小组试图通过蒙特卡洛树搜索、或使用数百万样本进行强化学习等技术来复现这些能力,但尚未有人能以开放且易于获取的方式,成功重现清晰的测试时扩展行为。
这项工作通过采用“最简单的方法”来解决这一空白,旨在同时实现强大的推理性能和测试时扩展。作者证明,仅需极少的资源——即 1,000 个训练样本以及在 16 张 H100 GPU 上进行 26 分钟的微调——即可取得具有竞争力的成果。
注释
-
Democratizing (民主化):在科技领域,指将昂贵、复杂或独占的技术转化为大众都能获取、使用和修改的形式。此处指让普通研究者和开发者也能使用强大的推理模型,而不必依赖 OpenAI 等大公司的闭源产品。
-
Monte Carlo Tree Search (蒙特卡洛树搜索):一种用于决策过程的启发式搜索算法,常用于游戏(如 AlphaGo)中模拟未来步骤。这里指过去有研究尝试用它来模仿模型的推理过程。
-
具有竞争力的成果:原文指模型的效果可以与顶尖模型(如 o1)相抗衡,并未被远远甩开,考虑到资源消耗极少,这在技术上是非常高效的成果。
-
H100 GPU:英伟达(NVIDIA)推出的一款高性能人工智能加速器,目前 AI 训练和推理的主流高端硬件。
Data Curation: Quality Over Quantity 数据筛选:质量胜于数量
The foundation of this approach lies in the careful curation of a small but highly effective dataset called s1K. Rather than using millions of synthetic examples, the researchers collected 59,000 questions from 16 diverse, high-quality sources including mathematical olympiad problems, PhD-level science questions, and quantitative reasoning tasks. From this pool, they selected exactly 1,000 samples using three key principles:
Quality: Questions with formatting errors or obvious flaws were filtered out, ensuring each example met high standards.
Difficulty: Only problems that stumped both Qwen2.5-7B-Instruct and Qwen2.5-32B-Instruct were included, guaranteeing genuine challenge.
Diversity: The final selection covered 50 different mathematical domains using the Mathematics Subject Classification system, ensuring broad coverage of reasoning skills.
该方法的基础在于对名为 s1K 的数据集进行了精心筛选,尽管规模不大,但做到了“小而精”。研究人员并未采用数百万个合成样本,而是从 16 个多元且高质量来源中收集了 59,000 道题目,包括奥数题、博士级科学问题和定量推理任务。在此基础上,他们依据三项核心原则,精准筛选出了 1,000 个样本:
-
质量:剔除了存在格式错误或明显瑕疵的题目,确保每个样本都符合高标准。
-
难度:仅纳入那些能同时难住
Qwen2.5-7B-Instruct和Qwen2.5-32B-Instruct两个模型的题目,以确保具备真正的挑战性。 -
多样性:最终选定的题目依据“数学学科分类系统”(MSC)涵盖了 50 个不同的数学领域,确保了对推理技能的广泛覆盖。
注释
-
Data Curation (数据策展/筛选):指从大量原始数据中挑选、清理和组织数据的过程。这里强调的是人工或半自动化的精细挑选,而非单纯的数据堆积。
-
Synthetic examples (合成样本):通常指由 AI 模型(如 GPT-4)生成的数据。研究人员特意避免使用这种方式,而是选择了真实且高质量的题目,以提升模型的学习效率。
-
Qwen2.5…Instruct:指阿里云通义千问 Qwen2.5 系列的指令微调版本。作者使用这两个型号作为“过滤器”,意味着他们只保留了连这些较强的现有模型都做不出来的题目,以此来训练模型突破当前的推理瓶颈。
-
Mathematics Subject Classification (MSC):数学学科分类系统,是由美国数学学会等机构制定的标准,用于对数学研究领域进行分类编号。
 Figure 2: The s1K dataset spans 50 diverse mathematical and scientific domains, from number theory and calculus to computer science and physics, ensuring comprehensive coverage of reasoning challenges. s1K 数据集横跨 50 个多元的数学与科学领域,从数论、微积分到计算机科学和物理学,确保了对各类推理挑战的全面覆盖。
Figure 2: The s1K dataset spans 50 diverse mathematical and scientific domains, from number theory and calculus to computer science and physics, ensuring comprehensive coverage of reasoning challenges. s1K 数据集横跨 50 个多元的数学与科学领域,从数论、微积分到计算机科学和物理学,确保了对各类推理挑战的全面覆盖。
For each question, detailed reasoning traces were generated using Google’s Gemini Flash Thinking API, creating step-by-step thought processes that demonstrate how to approach complex problems systematically.
Budget Forcing: A Simple Test-Time Intervention 预算强制:一种简单的测试时干预
The core innovation lies in “budget forcing,” a remarkably simple technique for controlling how much computational effort a model dedicates to thinking during inference. This method works by manipulating the model’s generation process in two ways:
Maximum Token Forcing: When the model exceeds a desired thinking budget, generation is terminated by forcefully inserting an end-of-thinking token, prompting the model to provide its final answer.
Minimum Token Forcing: To encourage more extensive reasoning, the model is prevented from ending its thought process early by suppressing the end-of-thinking token and appending the word “Wait” to its reasoning trace. This simple intervention nudges the model to continue exploring the problem space.
这项工作的核心创新在于“预算强制”,这是一项极其简单的技术,旨在控制模型在推理过程中投入多少算力。该方法通过以下两种方式操控模型的生成过程:
-
最大令牌强制:当模型超出预期的思考预算时,系统会通过强制插入一个“结束思考令牌”来终止生成过程,从而促使模型给出最终答案。
-
最小令牌强制:为了鼓励模型进行更充分的推理,系统通过抑制“结束思考令牌”并在其推理轨迹后追加“Wait”这个词,来阻止模型过早地结束思考。这一简单的干预措施引导模型继续探索问题空间。
注释
-
Budget Forcing (预算强制):直译为“预算强制”,这里的“预算”通常指的是计算资源,具体表现为生成的 Token(令牌)数量。该技术通过人为设定的上限和下限,强制控制模型的思考深度。
-
Intervention (干预):指在模型生成过程中的外部控制动作,而非改变模型参数的训练过程。
-
Reasoning Trace (推理轨迹):指模型生成最终答案之前所输出的思维链或中间推理步骤文本。
-
End-of-thinking Token (结束思考令牌):一种特殊的控制符(如
<|end_of_thought|>),用于标记模型思考阶段的结束和答案输出的开始。 -
Token (令牌):大模型处理文本的最小单位。这里的 Token 限制实际上就是对模型“思考长度”的限制。
 Figure 3: An example of the model’s reasoning process, showing how it can self-correct when given more thinking time. Initially answering “2” for the number of r’s in “raspberry,” the model reconsiders and correctly identifies all three occurrences. 模型推理过程的一个示例,展示了当给予更多思考时间时,模型如何进行自我纠正。起初,该模型将 “raspberry” 中 “r” 的数量回答为 “2”,但在重新思考后,它正确识别出了全部 3 处。
Figure 3: An example of the model’s reasoning process, showing how it can self-correct when given more thinking time. Initially answering “2” for the number of r’s in “raspberry,” the model reconsiders and correctly identifies all three occurrences. 模型推理过程的一个示例,展示了当给予更多思考时间时,模型如何进行自我纠正。起初,该模型将 “raspberry” 中 “r” 的数量回答为 “2”,但在重新思考后,它正确识别出了全部 3 处。
The elegance of this approach lies in its simplicity—no complex search algorithms or multi-agent systems are required. The model naturally learns to utilize additional thinking time when available, leading to improved performance on challenging reasoning tasks.
该方法的精妙之处在于其简洁性——无需复杂的搜索算法或多智能体系统。模型能够自然地学会利用额外的思考时间,进而提升其在高难度推理任务中的表现。
Results: Competitive Performance with Minimal Resources 结果:以极低资源实现极具竞争力的性能
The s1-32B model achieves remarkable results across multiple challenging benchmarks:
Test-Time Scaling: Clear monotonic improvement in performance as thinking tokens increase, successfully replicating the scaling behavior observed in OpenAI’s o1 model.
Competitive Performance: The model surpasses OpenAI’s o1-preview on competition mathematics problems by up to 27% and nearly matches Google’s Gemini 2.0 Thinking model on AIME24 problems.
Sample Efficiency: Most importantly, s1-32B achieves these results using just 1,000 training examples—a fraction of the 800,000+ samples used by comparable models like DeepSeek R1.
s1-32B 模型在多项具有挑战性的基准测试中取得了卓越的成果:
-
测试时扩展:随着思考令牌的增加,模型性能呈现清晰的单调增长趋势,成功复现了 OpenAI o1 模型中观察到的扩展行为。
-
极具竞争力的性能:在竞赛数学问题上,该模型的表现超越了 OpenAI 的 o1-preview,领先幅度最高达 27%;在 AIME24 问题上,其表现几乎与 Google 的 Gemini 2.0 Thinking 模型持平。
-
样本效率:最重要的是,s1-32B 仅使用了 1,000 个训练样本就取得了上述成果——这仅是 DeepSeek R1 等同类模型所使用的 800,000 多个样本的一小部分。
注释
-
测试时扩展:指在推理阶段通过增加计算资源(如思考时间或 Token 数量)来提升模型性能的能力。
-
单调增长:数学术语,指一个变量 consistently 随另一个变量增加而增加(或减少),在此处意味着思考时间越长,性能越好,没有出现倒退的情况。
-
AIME24:指 2024 年美国数学邀请赛,是衡量大模型数学推理能力的高难度基准数据集。
-
样本效率:指模型在达到特定性能水平时所需训练数据的多少。此处强调该模型用极少量数据就超越了使用海量数据的对手。
 Figure 4: The s1 model achieves competitive performance on MATH500 while using dramatically fewer training examples than other reasoning models, positioning it as the most sample-efficient approach. s1 模型在 MATH500 上取得了极具竞争力的表现,同时其所使用的训练样本数量远少于其他推理模型,使其成为样本效率最高的方法。
Figure 4: The s1 model achieves competitive performance on MATH500 while using dramatically fewer training examples than other reasoning models, positioning it as the most sample-efficient approach. s1 模型在 MATH500 上取得了极具竞争力的表现,同时其所使用的训练样本数量远少于其他推理模型,使其成为样本效率最高的方法。
Ablation Studies: Validating Design Choices 消融实验:验证设计选择
Extensive ablation studies confirm the importance of each component:
Data Curation Principles: Training on datasets that ignore quality, difficulty, or diversity criteria leads to significant performance drops (26-40% worse on AIME24).
Budget Forcing vs. Alternatives: Simple prompt-based methods for controlling thinking time prove unreliable, while rejection sampling surprisingly shows inverse scaling—longer generations often perform worse, suggesting that extended reasoning traces may indicate the model is struggling rather than thinking more deeply.
Training Efficiency: Using the full 59K sample dataset provides minimal gains over the curated 1K subset while requiring 56× more computational resources.
大量的消融实验证实了各个组件的重要性:
-
数据筛选原则:如果在训练中忽视质量、难度或多样性标准,会导致性能显著下降(在 AIME24 上的表现降低了 26-40%)。
-
预算强制与替代方案:用于控制思考时间的简单基于提示词的方法被证明并不可靠。相比之下,拒绝采样令人惊讶地展现出了“逆扩展”现象——生成的序列越长,表现反而越差。这表明,延长的推理轨迹可能意味着模型正陷入困境,而非在进行更深层次的思考。
-
训练效率:相比于筛选后的 1,000 个样本子集,使用完整的 5.9 万个样本数据集仅带来微乎其微的性能提升,却需要消耗 56 倍的计算资源。
注释
-
消融实验:机器学习中常用的一种方法,通过移除模型的某些组件(如特征、模块或训练步骤)来观察性能变化,从而验证这些组件的必要性。
-
预算强制:指强制限制模型在推理时使用的计算资源(如 Token 数量)的技术,旨在通过增加“思考”预算来提升性能。
-
逆扩展:一种反直觉的现象,通常指随着模型规模增大、计算量增加或训练数据增多,模型在某些任务上的表现反而下降。此处特指生成内容越长(推理痕迹越长),效果越差。
Combining Sequential and Parallel Scaling 结合顺序扩展与并行扩展
The research also explores how sequential scaling (where later computations build on earlier ones) can be combined with parallel scaling approaches. When integrated with techniques like REBASE (which generates multiple reasoning paths), the model can achieve even higher performance, suggesting that sequential and parallel approaches are complementary rather than competing strategies.
该研究还探讨了如何将顺序扩展(即后续计算构建于前序计算之上)与并行扩展方法相结合。当与 REBASE(一种生成多条推理路径的技术)等技术相结合时,模型能够实现更高的性能,这表明顺序方法与并行方法彼此互补,而非竞争关系。
注释
-
顺序扩展:指模型在推理时逐步生成内容,后一步的计算依赖于前一步的结果(类似于思维链 Chain-of-Thought)。
-
并行扩展:指模型同时生成多个不同的推理路径或答案,然后从中选择最好的一个(类似于思维树 Tree-of-Thoughts 或多数投票)。
-
互补:原文强调两种方法可以结合使用以产生协同效应,而不是二选一的关系。
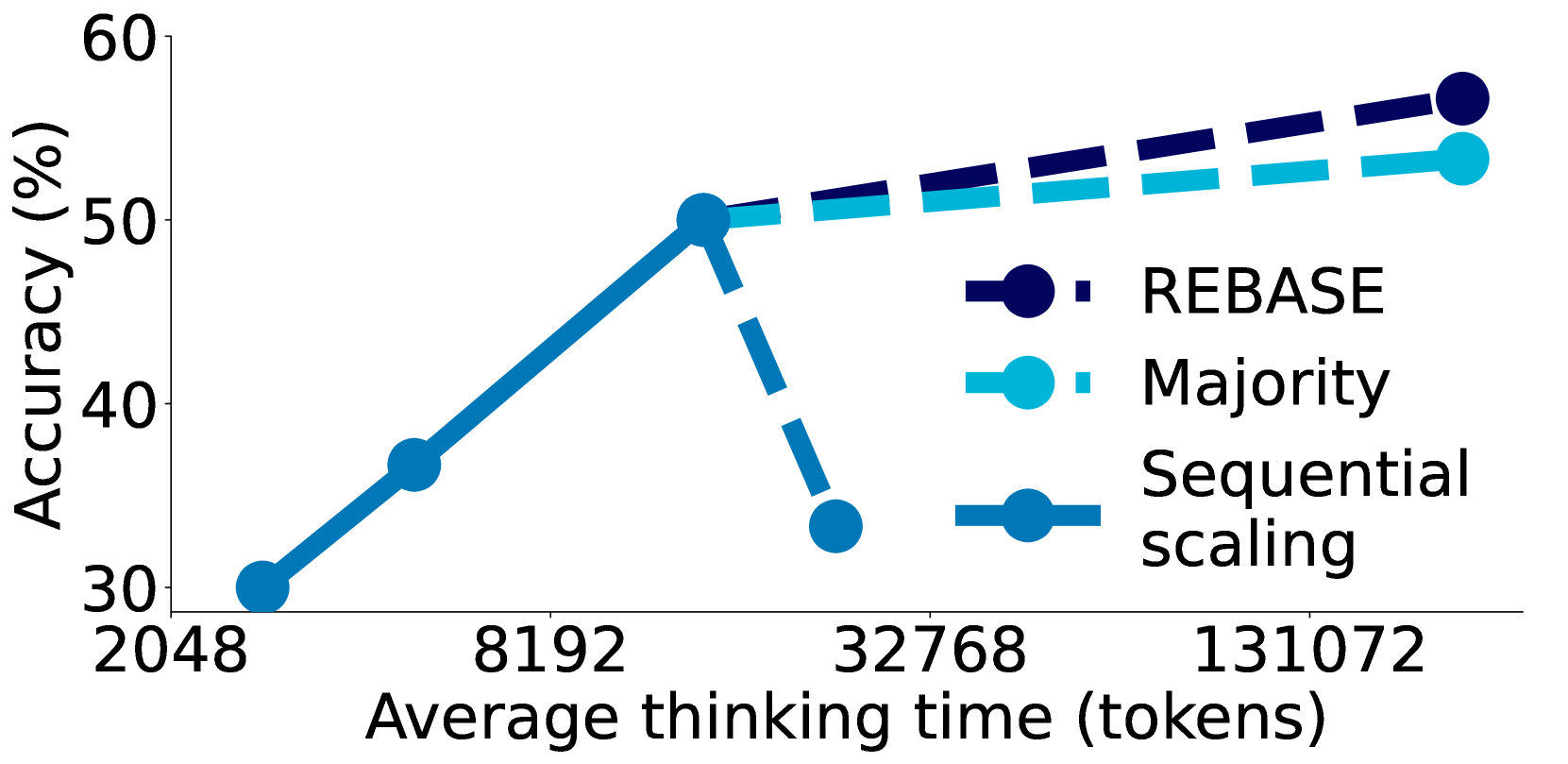 Figure 5: Comparison of sequential scaling (budget forcing) with parallel scaling methods (REBASE and majority voting) on AIME24, showing how different approaches can be combined for optimal performance. 在 AIME24 上顺序扩展(预算强制)与并行扩展方法(REBASE 和多数投票)的对比,展示了不同方法如何结合以实现最佳性能。
Figure 5: Comparison of sequential scaling (budget forcing) with parallel scaling methods (REBASE and majority voting) on AIME24, showing how different approaches can be combined for optimal performance. 在 AIME24 上顺序扩展(预算强制)与并行扩展方法(REBASE 和多数投票)的对比,展示了不同方法如何结合以实现最佳性能。
Significance and Impact 意义与影响
This work makes several important contributions to the field:
Democratizing Advanced AI: By providing a fully open-source model, dataset, and codebase, the research makes advanced reasoning capabilities accessible to researchers and organizations with limited resources.
Challenging Scale Assumptions: The success of the 1K-sample approach challenges the prevailing assumption that state-of-the-art performance requires massive datasets, suggesting that careful curation can be more valuable than scale.
Advancing Test-Time Scaling: The work provides the first open replication of clear test-time scaling behavior, opening new avenues for research into inference-time optimization.
Methodological Contributions: The introduction of budget forcing offers a simple yet effective alternative to complex search algorithms, while the evaluation metrics for test-time scaling methods provide a framework for future research.
The research demonstrates that the path to advanced AI capabilities need not require massive computational resources or proprietary methods. Through careful data curation and simple inference techniques, significant advances in reasoning performance can be achieved with surprising efficiency, making cutting-edge AI more accessible to the broader research community.
这项工作为该领域做出了几项重要贡献:
-
普及化先进 AI:通过提供完全开源的模型、数据集和代码库,本研究使资源有限的研究人员和组织也能获得先进的推理能力。
-
挑战规模假设:1,000 样本方法的成功挑战了主流观点,即认为获得最前沿(SOTA)的性能必须依赖海量数据集。这表明,精心的数据策展可能比数据规模更具价值。
-
推进测试时扩展:本研究提供了首个对清晰测试时扩展行为的开源复现,为推理时优化的研究开辟了新途径。
-
方法论贡献:“预算强制”的引入提供了一种简单但有效的替代方案,用以替代复杂的搜索算法;同时,针对测试时扩展方法的评估指标也为未来的研究提供了评估框架。
这项研究表明,通往先进 AI 能力的道路未必需要巨大的计算资源或专有方法。通过精心的数据策展和简单的推理技术,可以以惊人的效率在推理性能上取得重大进展,从而使更广泛的研究界能够接触到前沿的 AI 技术。
注释
-
普及化:指降低技术门槛,使更多人能够使用和接触原本昂贵或封闭的技术。
-
数据策展:在此语境下,指对数据进行精心筛选、整理和优化的过程(对应前文的 Data Curation)。相比单纯追求数据数量,“策展”更强调对数据质量的把控。
-
测试时扩展:指在模型推理(测试)阶段通过增加计算量(如延长思考时间)来提升性能的方法。文中强调这是首次有开源研究成功复现了这一行为。
-
专有方法:指不公开源代码、仅由特定公司内部掌握的技术。作者强调通过开源和高效方法,打破了这种技术壁垒。
Relevant Citations
Learning to reason with llms This paper introduces the o1 model, whose test-time scaling capabilities directly motivated the research in the main paper. The s1 model is presented as a simple, open-source replication of the behavior demonstrated by o1, and o1’s performance is used as a key benchmark throughout the analysis. OpenAI.Learning to reason with llms, September 2024. URLhttps://openai.com/index/learning-to-reason-with-llms/.
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning The DeepSeek-r1 model is a primary point of comparison used to highlight the sample efficiency of the s1 model. The paper contrasts its simple, 1,000-sample SFT approach with DeepSeek-r1’s more complex reinforcement learning method that relies on a much larger dataset to achieve strong reasoning performance. DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao, G., Chen, G., Li, G., Zhang, H., Bao, H., Xu, H., Wang, H., Ding, H., Xin, H., Gao, H., Qu, H., Li, H., Guo, J., Li, J., Wang, J., Chen, J., Yuan, J., Qiu, J., Li, J., Cai, J. L., Ni, J., Liang, J., Chen, J., Dong, K., Hu, K., Gao, K., Guan, K., Huang, K., Yu, K., Wang, L., Zhang, L., Zhao, L., Wang, L., Zhang, L., Xu, L., Xia, L., Zhang, M., Zhang, M., Tang, M., Li, M., Wang, M., Li, M., Tian, N., Huang, P., Zhang, P., Wang, Q., Chen, Q., Du, Q., Ge, R., Zhang, R., Pan, R., Wang, R., Chen, R. J., Jin, R. L., Chen, R., Lu, S., Zhou, S., Chen, S., Ye, S., Wang, S., Yu, S., Zhou, S., Pan, S., Li, S. S., Zhou, S., Wu, S., Ye, S., Yun, T., Pei, T., Sun, T., Wang, T., Zeng, W., Zhao, W., Liu, W., Liang, W., Gao, W., Yu, W., Zhang, W., Xiao, W. L., An, W., Liu, X., Wang, X., Chen, X., Nie, X., Cheng, X., Liu, X., Xie, X., Liu, X., Yang, X., Li, X., Su, X., Lin, X., Li, X. Q., Jin, X., Shen, X., Chen, X., Sun, X., Wang, X., Song, X., Zhou, X., Wang, X., Shan, X., Li, Y. K., Wang, Y. Q., Wei, Y. X., Zhang, Y., Xu, Y., Li, Y., Zhao, Y., Sun, Y., Wang, Y., Yu, Y., Zhang, Y., Shi, Y., Xiong, Y., He, Y., Piao, Y., Wang,Y., Tan, Y., Ma, Y., Liu, Y., Guo, Y., Ou, Y., Wang, Y., Gong, Y., Zou, Y., He, Y., Xiong, Y., Luo, Y., You, Y., Liu, Y., Zhou, Y., Zhu, Y. X., Xu, Y., Huang, Y., Li, Y., Zheng, Y., Zhu, Y., Ma, Y., Tang, Y., Zha, Y., Yan, Y., Ren, Z. Z., Ren, Z., Sha, Z., Fu, Z., Xu, Z., Xie, Z., Zhang, Z., Hao, Z., Ma, Z., Yan, Z., Wu, Z., Gu, Z., Zhu, Z., Liu, Z., Li, Z., Xie, Z., Song, Z., Pan, Z., Huang, Z., Xu, Z., Zhang, Z., and Zhang, Z. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
Lima: Less is more for alignment This paper provides the conceptual foundation for the main paper’s sample-efficient methodology. The authors explicitly connect their finding that a small, curated dataset of 1,000 examples is sufficient for strong reasoning to the “Superficial Alignment Hypothesis” proposed in LIMA, which argued that most knowledge is learned during pretraining and only needs a small amount of data for alignment. Zhou, C., Liu, P., Xu, P., Iyer, S., Sun, J., Mao, Y., Ma, X., Efrat, A., Yu, P., Yu, L., Zhang, S., Ghosh, G., Lewis, M., Zettlemoyer, L., and Levy, O. Lima: Less is more for alignment, 2023. URLhttps://arxiv.org/abs/2305.11206.
Scaling llm test-time compute optimally can be more effective than scaling model parameters This work is cited for providing the crucial classification of test-time scaling methods into ‘sequential’ and ‘parallel’ approaches, a framework the main paper adopts for its analysis. It is a foundational contemporary paper on the core topic of test-time scaling, providing important context for the paper’s methods and contributions. Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024. URLhttps://arxiv.org/abs/2408.03314.