Journal
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning

Summary
Researchers at Carnegie Mellon University introduced Length Controlled Policy Optimization (LCPO), an RL-based method that trains large language models to precisely control the length of their reasoning steps. This approach enables dynamic trade-offs between computational cost and accuracy, achieving over 100% relative performance gains compared to heuristic methods and yielding powerful “Short Reasoning Models” that surpass larger frontier models like GPT-4o.
卡内基梅隆大学的研究人员推出了 长度控制策略优化(LCPO)。这是一种基于强化学习的方法,旨在训练大语言模型精确控制其推理步骤的长度。该方法实现了计算成本与准确性之间的动态权衡;与启发式方法相比,它实现了超过 100% 的相对性能提升,并产出了强大的 “短推理模型”,其表现甚至超越了 GPT-4o 等规模更大的前沿模型。
注释
-
长度控制策略优化:这是原文中提到的核心算法名称。在强化学习(RL)领域,“Policy Optimization” 指的是优化模型决策策略的技术,此处特指针对推理长度进行控制的优化。
-
基于强化学习的(RL-based):指利用智能体通过与环境交互并获得奖励反馈来学习策略的方法。在这里,模型通过训练学会了如何在保持准确性的同时调整推理过程的长度。
-
启发式方法:指依据经验法则或既定规则解决问题的方法(例如强制模型在特定步数后停止)。相比之下,LCPO 让模型自主学习最佳停止点,因此能获得显著的性能提升。
-
前沿模型:指在特定时间点内技术最先进、性能最顶尖的模型家族(如 GPT-4o、Claude 3 等)。这句话强调了“短推理模型”在效率上的优势,足以战胜参数量更大的顶级模型。
Introduction
Modern reasoning language models have demonstrated remarkable capabilities by generating extended “chain-of-thought” sequences that improve performance on complex problems. However, these models suffer from a critical limitation: they cannot precisely control how long they “think” during inference. This unpredictability makes it challenging to deploy reasoning models in production environments where computational budgets and response times must be managed efficiently.
现代推理语言模型通过生成长序列的“思维链”,展现出了卓越的能力,从而显著提升了其在解决复杂问题时的表现。然而,这些模型存在一个关键的局限:它们无法精确控制在推理过程中“思考”的时长。这种不可预测性给推理模型在生产环境中的部署带来了巨大挑战,因为在这些环境中,必须对算力预算和响应时间进行高效管理。
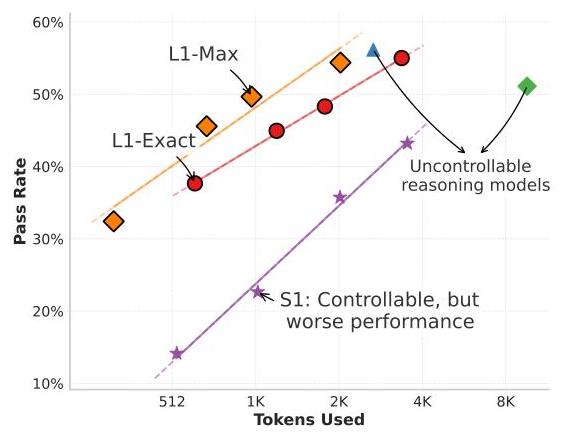 Figure 1: Performance comparison showing L1 models (L1-Exact and L1-Max) achieving smooth trade-offs between tokens used and pass rate, significantly outperforming prior methods like S1 and matching unconstrained reasoning models at optimal lengths. 性能对比显示,L1 模型(L1-Exact 和 L1-Max)在 Token 使用量和通过率之间实现了平滑的权衡,显著优于 S1 等先前方法,且在最佳长度下能够媲美无约束的推理模型。
Figure 1: Performance comparison showing L1 models (L1-Exact and L1-Max) achieving smooth trade-offs between tokens used and pass rate, significantly outperforming prior methods like S1 and matching unconstrained reasoning models at optimal lengths. 性能对比显示,L1 模型(L1-Exact 和 L1-Max)在 Token 使用量和通过率之间实现了平滑的权衡,显著优于 S1 等先前方法,且在最佳长度下能够媲美无约束的推理模型。
注释
-
通过率:在大模型推理能力的评测中(如数学题 GSM8K 或 MATH 数据集),“通过率”指模型正确解决问题的比例。
-
平滑的权衡:指模型能够根据分配的 Token 数量,稳定地调整性能。简单来说,给更多的思考时间,准确率就稳步上升,而不是出现剧烈的波动或不可预测的变化。
-
无约束的推理模型:指没有对推理链长度进行任何限制的模型。这些模型通常使用尽可能多的 Token 来回答问题,以达到最高准确率,但计算成本很高。这句话表明 L1 模型在控制了成本(长度)的情况下,依然能达到和那些“不计成本”的模型一样的效果。
-
S1:指本研究中对比的基线方法之一(可能指代某一种简单的扩展方法或特定的早期模型),此处保留原名以示准确。
Researchers Pranjal Aggarwal and Sean Welleck from Carnegie Mellon University address this fundamental challenge in their paper “L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning.” They introduce Length Controlled Policy Optimization (LCPO), a reinforcement learning approach that trains reasoning models to generate outputs that precisely adhere to user-specified token budgets while maintaining high accuracy.
来自卡内基梅隆大学的研究人员 Pranjal Aggarwal 和 Sean Welleck 在其论文《L1:利用强化学习控制推理模型的思考时长》中,针对这一根本性挑战提出了解决方案。他们介绍了长度控制策略优化(LCPO),这是一种强化学习方法,旨在训练推理模型在保持高准确率的同时,生成严格遵循用户指定 Token 预算的输出。
The Problem with Existing Approaches 现有方法存在的问题
Current reasoning language models generate chain-of-thought sequences of unpredictable length. While longer reasoning often improves accuracy, this uncontrolled generation creates several problems. Models may waste computational resources on unnecessarily long sequences or terminate prematurely on complex problems. Previous attempts to impose length control, such as the S1 method which uses budget-forcing with special tokens, have proven largely ineffective and often severely degrade reasoning performance.
The core challenge lies in maintaining the integrity of the reasoning process while adhering to length constraints. Simple truncation disrupts logical flow, while rigid budget enforcement fails to adapt to problem complexity. This creates a need for intelligent, adaptive length control that can dynamically adjust reasoning strategies based on both the problem at hand and the available computational budget.
现有的推理语言模型生成的思维链序列长度往往不可预测。虽然较长的推理过程通常能提高准确率,但这种不受控制的生成会引发诸多问题。模型可能会在不必要地长序列上浪费算力资源,或是面对复杂问题时过早终止推理。此前施加长度控制的尝试——例如 S1 方法(该方法利用特殊 Token 强制执行预算)——已被证明基本无效,且往往会严重降低推理性能。
核心挑战在于,在遵守长度约束的同时,维持推理过程的完整性。简单的截断会破坏逻辑连贯性,而僵化的预算强制机制无法适应问题的复杂度。因此,我们需要一种智能、自适应的长度控制机制,它能够根据当前面临的具体问题和可用的算力预算,动态调整推理策略。
注释
-
思维链序列:指模型为了得出答案而生成的中间推理步骤的序列。
-
过早终止:指模型在还未完成必要的推理步骤时就停止了生成,导致未给出完整或正确答案。
-
S1 方法:此处指代论文中作为对比对象的一种特定基线方法。
-
预算强制:一种技术手段,指在模型生成过程中,通过预设的标记强行要求其在特定的资源额度(如 Token 数量)内完成任务,通常带有强迫性而非引导性。
-
完整性:指推理过程逻辑严密、结构完整,没有被突然切断或破坏。如果强行截断,可能会导致逻辑突然断裂,答案出错。
-
自适应:指模型不是死板地遵守规则,而是能根据具体情况(如题目难易)灵活调整行为的能力。
Length Controlled Policy Optimization (LCPO)
LCPO fine-tunes pre-trained reasoning models using reinforcement learning to achieve precise length control. The method augments input prompts with target length instructions (e.g., “Think for 1024 tokens”) and optimizes the model to simultaneously produce correct answers and match the specified length.
The approach uses two distinct reward functions. The LCPO-Exact reward function balances correctness and exact length adherence:
where provides a reward of 1 for correct answers, and the penalty term scales with the absolute difference between target length () and generated length ().
For scenarios requiring maximum budget constraints rather than exact lengths, LCPO-Max uses:
This variant encourages staying within budget while providing gradient information for the reinforcement learning objective. The authors trained their L1 models using GRPO (Group Relative Policy Optimization) on a mathematics reasoning dataset, with target lengths sampled uniformly between 100 and 4000 tokens.
LCPO 利用强化学习对预训练推理模型进行微调,以实现精确的长度控制。该方法通过添加目标长度指令来增强输入提示词(例如“思考 1024 个 Token”),并优化模型,使其在生成正确答案的同时,符合指定的长度要求。
该方法采用了两种不同的奖励函数。LCPO-Exact 奖励函数在正确性和精确长度遵循之间取得了平衡:
其中, 表示指示函数:当答案正确时提供 1 的奖励;惩罚项 则根据目标长度 () 与生成长度 () 之间的绝对差值进行线性缩放。
对于需要最大预算约束而非精确长度的场景,LCPO-Max 使用以下公式:
该变体旨在鼓励模型保持在预算范围内,同时为强化学习目标提供梯度信息。作者在数学推理数据集上利用 GRPO(组相对策略优化)对其 L1 模型进行了训练,目标长度在 100 到 4000 个 Token 之间均匀采样。
Experimental Results and Performance
The L1 models demonstrate remarkable improvements over existing baselines across multiple mathematics reasoning benchmarks. Compared to the S1 budget-forcing method, L1 achieves 100-150% relative performance improvements, with absolute gains of 20-25% at constrained token budgets like 512 and 1024 tokens.
L1 模型在多个数学推理基准测试中展现了优于现有基线方法的显著提升。与 S1 预算强制方法相比,L1 实现了 100-150% 的相对性能提升;在 512 和 1024 个 Token 的受限预算下,其绝对性能增益达到了 20-25%。
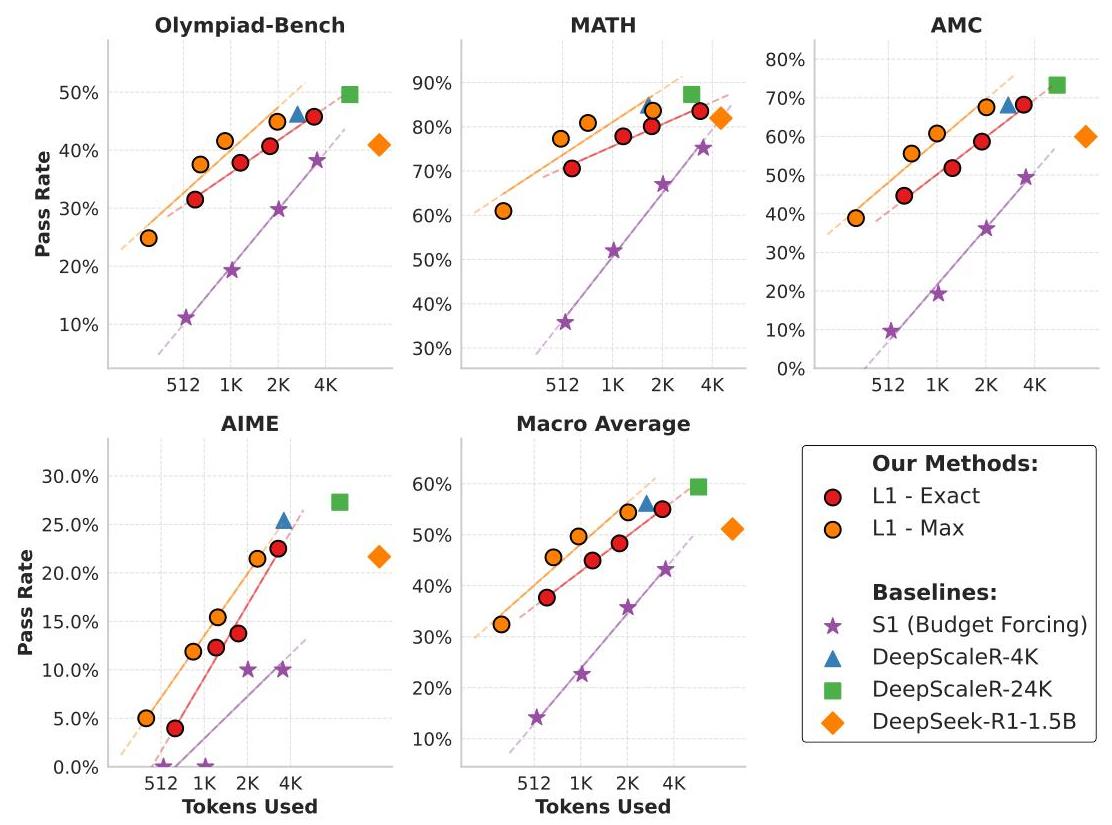 Figure 2: Performance across math reasoning benchmarks showing L1 models consistently outperforming baselines while maintaining precise length control. The smooth scaling demonstrates effective trade-offs between computational cost and accuracy. 数学推理基准上的性能表现显示,L1 模型在维持精确长度控制的同时始终优于基线模型。平滑的扩展曲线展示了计算成本与准确率之间有效的权衡。
Figure 2: Performance across math reasoning benchmarks showing L1 models consistently outperforming baselines while maintaining precise length control. The smooth scaling demonstrates effective trade-offs between computational cost and accuracy. 数学推理基准上的性能表现显示,L1 模型在维持精确长度控制的同时始终优于基线模型。平滑的扩展曲线展示了计算成本与准确率之间有效的权衡。
The models maintain high precision in length adherence, with mean deviations from target lengths as low as 3% on mathematics datasets. Even on out-of-domain tasks like logical reasoning (LSAT, GPQA) and general knowledge (MMLU), L1 models generalize effectively, showing consistent performance scaling with increased token budgets.
模型在长度遵循方面保持了极高的精度,在数学数据集上,相对于目标长度的平均偏差仅为 3%。即使在逻辑推理(LSAT、GPQA)和通用知识(MMLU)等跨领域任务中,L1 模型也表现出良好的泛化能力,并且随着 Token 预算的增加,其性能呈现出一致的扩展趋势。
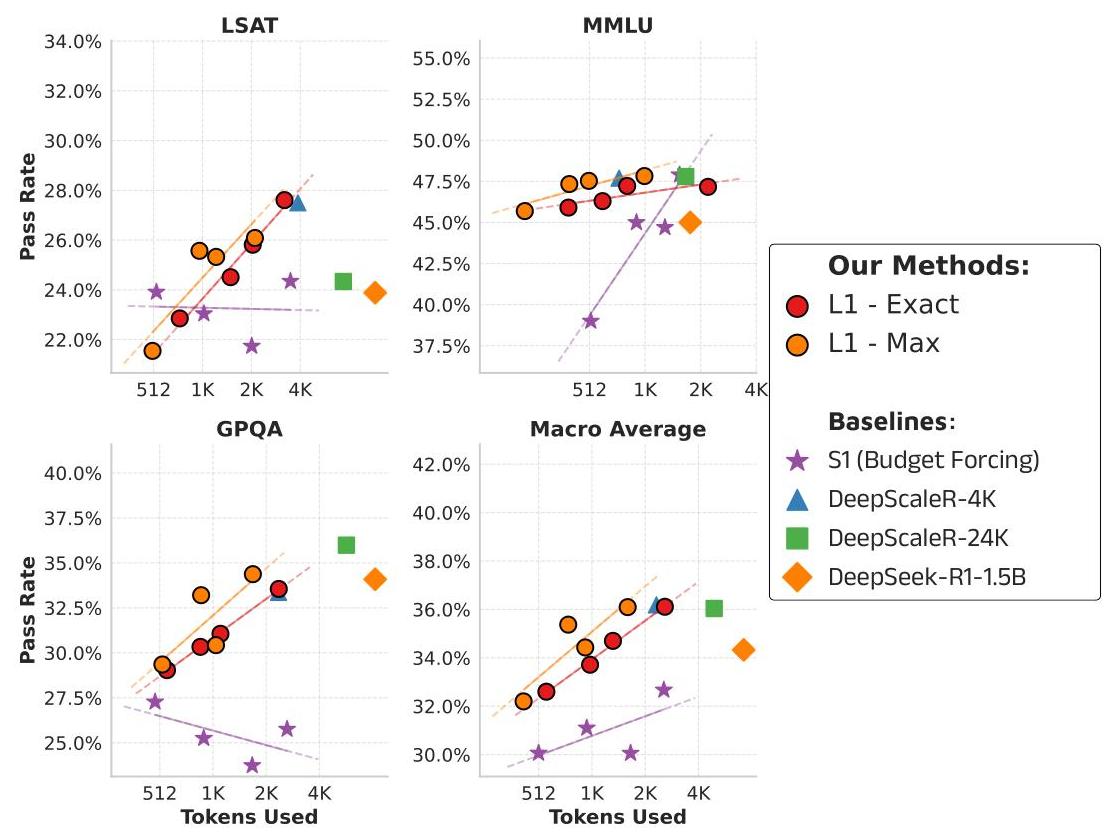 Figure 3: Generalization to out-of-domain tasks demonstrates that L1’s length control capabilities extend beyond the training distribution, maintaining performance scaling on diverse reasoning tasks. 针对跨领域任务的泛化测试表明,L1 的长度控制能力不仅适用于训练分布范围,还能在多样化的推理任务上保持性能扩展趋势。
Figure 3: Generalization to out-of-domain tasks demonstrates that L1’s length control capabilities extend beyond the training distribution, maintaining performance scaling on diverse reasoning tasks. 针对跨领域任务的泛化测试表明,L1 的长度控制能力不仅适用于训练分布范围,还能在多样化的推理任务上保持性能扩展趋势。
注释
-
相对性能提升:这是一个百分比增长的概念。例如,如果基线方法 S1 的准确率是 20%,而 L1 的准确率是 40%,那么绝对增益是 20%(40%-20%),而相对提升则是 100%((40%-20%)/20%)。这意味着 L1 的表现是 S1 的两倍,提升非常巨大。
-
绝对增益:指准确率数值的直接增加量(例如从 50% 提升到 70%,绝对增益就是 20%)。
-
长度遵循:指模型执行“将其输出长度限制在指定范围内”这一指令的能力。
-
平均偏差:统计学概念,指模型实际生成的长度与目标长度之间差值的平均值。偏差 3% 意味着如果要求生成 1000 个 Token,模型平均只差 30 个左右,控制得非常精准。
-
跨领域任务:指与模型训练数据集分布不同的任务。L1 是在数学数据集上训练的,但在逻辑推理(LSAT, GPQA)和常识问答(MMLU)上依然有效,说明学到的“控制长度”的能力具有通用性,不只是死记硬背数学题。
-
性能扩展:指随着投入资源(这里是 Token 预算)的增加,性能相应提升的规律。“一致的扩展趋势”意味着给模型更多的思考预算,它的表现就会稳步变好,符合预期。
-
平滑的扩展:指图中的性能曲线随着资源(Token 数)的增加而平滑上升,没有出现剧烈的波动或停滞,表明模型在增加计算投入时能稳定地获得更高的准确率。
-
权衡:指在追求准确率的同时需要付出计算成本作为代价。这里的意思是该模型找到了一个平衡点,即合理利用计算成本以换取准确率的提升。
-
跨领域任务的泛化:指模型在处理与训练数据类型不同的任务时的表现能力(例如用数学题训练的模型去处理逻辑题)。
-
训练分布:机器学习术语,指模型在训练过程中所见数据的统计规律。“超出训练分布范围”意味着面对的数据特征与训练时有所不同。
Length Adherence and Adaptive Strategies 长度遵循与自适应策略
One of LCPO’s most impressive achievements is its precision in length control. The models learn to generate outputs that closely match target lengths across different token budgets, as shown in the length distribution analysis.
LCPO 最令人瞩目的成就之一是其在长度控制方面的高精度。正如长度分布分析所示,模型学会了生成与目标长度高度吻合的输出,且这一能力适用于不同的 Token 预算范围。
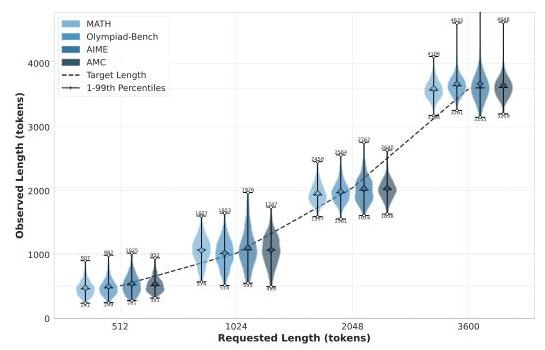 Figure 4: Violin plots showing precise length control across different target lengths. The tight distributions around target lengths (dashed lines) demonstrate the effectiveness of LCPO training. 展示不同目标长度下精确长度控制的小提琴图。数据围绕目标长度(虚线)的紧密分布证明了 LCPO 训练的有效性。
Figure 4: Violin plots showing precise length control across different target lengths. The tight distributions around target lengths (dashed lines) demonstrate the effectiveness of LCPO training. 展示不同目标长度下精确长度控制的小提琴图。数据围绕目标长度(虚线)的紧密分布证明了 LCPO 训练的有效性。
Analysis of the models’ reasoning patterns reveals adaptive strategies based on available token budgets. When given more tokens, models employ more “self-correction and verification” and “conclusion drawing” terms. The ratio of thinking tokens to solution tokens remains relatively stable, indicating efficient resource allocation across different generation lengths.
对模型推理模式的分析揭示了一种基于可用 Token 预算的自适应策略。当获得更多 Token 时,模型会增加使用“自我纠正与验证”以及“得出结论”类表述的频次。思考 Token 与解答 Token 的比例保持相对稳定,表明模型在不同的生成长度下均能实现高效的资源分配。
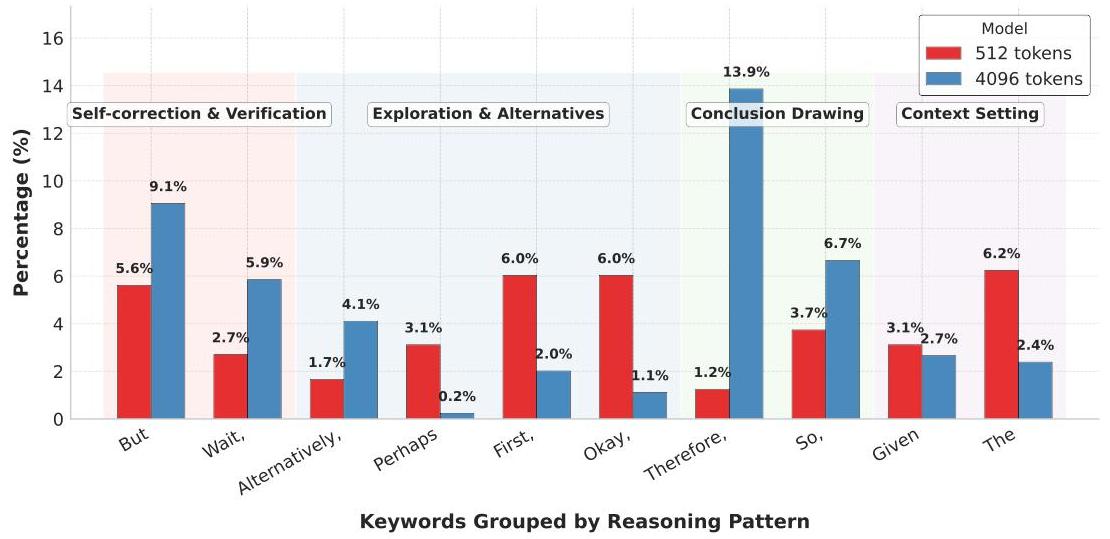 Figure 5: Keyword analysis revealing how L1 adapts its reasoning patterns based on token budget. Longer sequences feature more self-correction and verification, while maintaining consistent reasoning structure. 关键词分析揭示了 L1 如何依据 Token 预算调整其推理模式。更长的序列呈现出更多的自我纠正与验证行为,同时保持了推理结构的一致性。
Figure 5: Keyword analysis revealing how L1 adapts its reasoning patterns based on token budget. Longer sequences feature more self-correction and verification, while maintaining consistent reasoning structure. 关键词分析揭示了 L1 如何依据 Token 预算调整其推理模式。更长的序列呈现出更多的自我纠正与验证行为,同时保持了推理结构的一致性。
注释
-
长度遵循:指模型在生成内容时,严格遵守预设长度的能力。这里是衡量模型可控性的关键指标。
-
自适应策略:指模型并非机械地填充内容,而是根据“预算”(允许生成的 Token 数量)的多少,动态调整其写作或推理方式。
-
“自我纠正与验证”和“得出结论”类表述:原文为“terms”,在此处指模型在生成思维链时,表达特定认知步骤的短语或句子。模型发现预算宽裕时,会花更多精力去回过头检查错误或清晰地总结结论,而不是仅仅列出推导步骤。
-
思考 Token:指模型用于生成中间推理过程(即思维链)的 Token 数量。这部分内容通常是隐藏的或作为辅助思考的,不直接作为最终答案展示给用户(取决于具体架构,但在 LCPO 语境下通常指 CoT 部分)。
-
解答 Token:指模型用于生成最终答案的 Token 数量。
-
资源分配:此处将生成的 Token 总数看作一种“计算资源”或“预算”。比例稳定意味着模型不会因为预算多了就只在思考里废话,也不会因为预算少了就完全放弃思考直接给答案,而是维持了“思考过程”与“最终答案”之间相对合理的比例关系。
-
小提琴图:一种用于可视化数值数据分布的统计图表。它结合了箱线图和核密度图的特征,不仅显示数据的概要统计(如中位数、四分位数),还能展示数据的分布密度形状(即“胖瘦”)。
-
紧密分布:指数据点非常集中地聚集在平均值或目标值附近。在图表上,这意味着小提琴图在某处非常“瘦”且“高”,说明模型生成的长度非常精准,很少有太长或太短的情况。
-
关键词分析:一种文本分析方法,通过统计或识别特定类型的词汇(如“检查”、“验证”、“因此”)来了解模型在生成过程中的思维活动和行为模式。
-
序列:在本文语境下指模型生成的 Token 序列,即模型输出的文本内容。
-
推理结构的一致性:意味着无论生成的文本长短,模型遵循的逻辑框架(例如:分析 -> 推导 -> 结论)是不变的。这表明模型不是因为“凑字数”而胡乱增加内容,而是在原有逻辑框架内增加了细节或检查步骤。
Short Reasoning Models: An Unexpected Discovery 短推理模型:一项意外发现
Perhaps the most intriguing finding is that models trained to generate longer reasoning chains also become exceptionally capable at short reasoning. These “Short Reasoning Models” (SRMs) consistently outperform much larger frontier models like GPT-4o and Llama-3.3-70B when operating under equivalent short token budgets.
This discovery challenges conventional scaling assumptions, suggesting that effective reinforcement learning can enable smaller models to achieve disproportionate reasoning capabilities. The 1.5B parameter L1 model surpasses GPT-4o by 2% on average when both are constrained to similar reasoning lengths, demonstrating that intelligent training can partially compensate for parameter count differences.
或许最引人注目的发现是,那些经过训练以生成长推理链的模型,在短推理任务中也展现出了卓越的能力。这些“短推理模型”(SRMs)在等效的短 Token 预算限制下运行时,其性能始终优于规模大得多的前沿模型,如 GPT-4o 和 Llama-3.3-70B。
这一发现挑战了传统的缩放假设,表明有效的强化学习能够赋能小模型,使其获得与其规模不相称的推理能力。当两者都被限制在相似的推理长度时,拥有 15 亿参数的 L1 模型的平均表现超越 GPT-4o 2%,这证明了智能训练可以部分弥补参数数量上的差异。
注释
-
短推理模型:指在限制非常少的 Token 数量(即简短输出)的情况下,仍能保持高质量推理能力的模型。
-
前沿模型:指在特定时间段内,性能处于最顶尖水平、代表了技术最前沿的通用大语言模型。
-
传统的缩放假设:通常指“缩放定律”,即认为模型的性能随着参数数量、训练数据量和计算资源的增加而可预测地提升。本文的发现表明,不一定非要单纯通过增大模型尺寸(即“缩放”)来获得更好的性能,优化训练方法同样甚至更有效。
-
与其规模不相称的:原文为 “disproportionate”,在此语境下是褒义,指小模型展现出了远超其尺寸(参数量)所能预期的强大能力,打破了“性能与大小成正比”的刻板印象。
Technical Robustness and Scaling
Extensive ablation studies confirm LCPO’s design choices. Supervised fine-tuning proves ineffective for length control, highlighting the necessity of online reinforcement learning with length-sensitive rewards. The multiplicative reward formulation for LCPO-Max prevents collapse to trivially short sequences while maintaining gradient flow.
大量的消融实验证实了 LCPO 的设计决策。研究证明,有监督微调(SFT)在长度控制方面是无效的,这凸显了采用“具有长度感知能力的在线强化学习”的必要性。对于 LCPO-Max 而言,其乘法奖励机制有效防止了模型退化生成极短的序列,同时保持了梯度的顺畅传播。
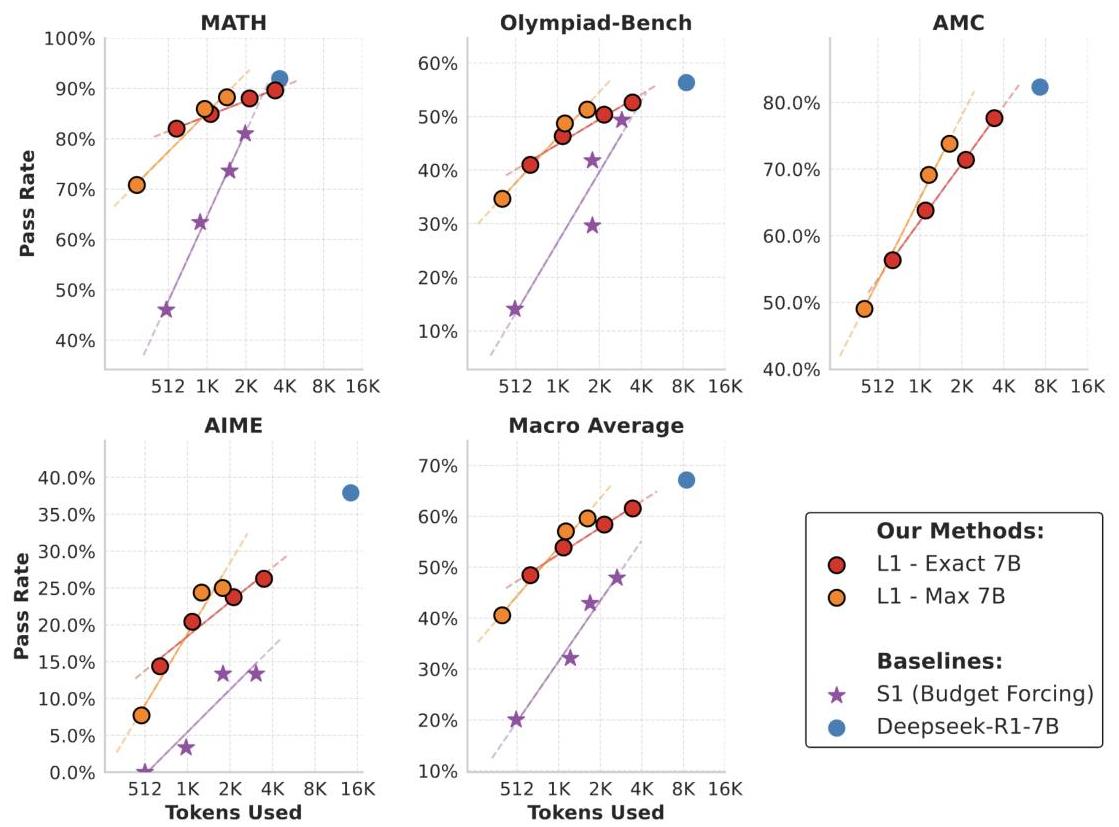 Figure 6: LCPO successfully scales to larger 7B models, maintaining similar performance improvements and length control capabilities across different model sizes.
Figure 6: LCPO successfully scales to larger 7B models, maintaining similar performance improvements and length control capabilities across different model sizes.
The approach scales successfully to larger models, with 7B parameter versions showing similar benefits. Length control remains robust across different sampling temperatures and decoding strategies, indicating practical deployability across various inference configurations.
该方法成功扩展至规模更大的模型,70 亿参数(7B)版本也展现出了类似的收益长度控制能力在不同的采样温度和解码策略下始终保持稳健,这表明该方法具备在各种推理配置下进行实际部署的潜力。
注释
-
消融实验:机器学习中常用的一种验证方法。通过移除模型的某个组件(如去掉某层网络或去掉某种奖励机制),观察模型性能是否下降,从而确认该组件的必要性和贡献。
-
有监督微调:指使用带有标准答案的标注数据对预训练模型进行进一步训练。文中提到它对长度控制“无效”,意味着仅仅让模型模仿标准答案的长度,无法让模型学会灵活应对不同长度限制的能力。
-
在线强化学习:指模型在训练过程中不断与环境(这里是自身生成的输出)交互,并根据反馈实时更新策略,而不是使用固定的离线数据集。
-
坍缩至极短序列:在强化学习中,模型可能会为了获得高分而寻找“捷径”。如果不限制长度,模型可能会发现只生成几个字的答案最容易得分,从而导致输出质量的退化。这里的“坍缩”指的就是这种丧失复杂生成能力、退化为简单模式的现象。
-
梯度流:指在神经网络反向传播过程中,梯度信息从输出层流向输入层的顺畅程度。保持梯度流意味着模型能够有效地学习,不会出现梯度消失或爆炸的问题。
-
采样温度:控制模型生成随机性的一个参数。温度高,输出更随机、更有创意;温度低,输出更确定、保守。文中提到长度控制在不同温度下都“稳健”,意味着无论用户想要更有创意的回答还是更保守的回答,模型都能精准控制长度。
-
解码策略:指生成文本的具体算法规则,如贪婪搜索、集束搜索等。
Implications and Future Directions 启示与未来展望
This work represents a significant advancement in making reasoning language models more practical and efficient. By providing precise control over computational allocation, LCPO enables organizations to optimize inference costs while maintaining desired performance levels. The discovery of effective short reasoning models suggests new possibilities for deploying capable AI systems in resource-constrained environments.
The research opens several promising directions, including exploration of more sophisticated reward functions, integration with other test-time optimization techniques, and investigation of length control for other types of language model outputs beyond mathematical reasoning. The demonstrated generalizability to out-of-domain tasks suggests that LCPO could become a foundational technique for controllable generation in production AI systems.
LCPO’s success in creating adaptive, efficient reasoning models while maintaining high performance standards makes it a valuable contribution to the ongoing effort to make advanced language models more practical and deployable across diverse real-world applications.
这项研究在提升推理语言模型的实用性与效率方面取得了重大进展。通过对计算资源分配的精确控制,LCPO 使组织能够在维持理想性能水平的同时,优化推理成本。高效短推理模型的发现,为在资源受限环境中部署强大的 AI 系统开辟了新的可能性。
该研究指出了几个充满前景的方向,包括探索更复杂的奖励函数、与其他测试时优化技术的整合,以及针对除数学推理以外其他类型的语言模型输出进行长度控制的研究。LCPO 在域外任务上所展现出的泛化能力表明,它有望成为生产级 AI 系统中“可控生成”的一项基础性技术。
LCPO 成功构建了既自适应又高效的推理模型,同时保持了高标准的性能,这为致力于让先进语言模型在多元化的现实应用中更加实用且更易于部署的持续努力,做出了宝贵的贡献。
注释
-
计算资源分配:原文为 “computational allocation”。在推理过程中,计算资源通常与生成的 Token 数量成正比。精确控制长度意味着精确控制消耗的算力,从而更有效地利用 GPU 等硬件资源。
-
资源受限环境:指算力、内存或电力有限的场景,例如边缘设备(手机、物联网设备)、本地部署的服务器或预算受限的云环境。
-
测试时优化:指在模型推理阶段(即使用模型生成答案时)动态调整参数或策略以提升性能的技术,相对于“训练时优化”而言。
-
域外任务:指超出模型训练数据范围或特定训练任务场景以外的任务。如果模型在域外任务上表现良好,说明它掌握了通用的能力,而不仅仅是死记硬背了训练题。
-
可控生成:指能够按照用户指定的约束(如长度、风格、关键词、情感等)来生成文本的技术。这是大模型落地应用的关键能力之一。
-
生产级 AI 系统:指已经过充分测试和优化,具备高稳定性、高可靠性,可以投入实际商业产品或工业环境中运行的系统,而非仅限于实验室研究的原型。