Journal
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

Summary
总结
DeepSeek-AI developed DeepSeek-R1, an LLM demonstrating that sophisticated reasoning capabilities can emerge through pure outcome-based reinforcement learning without reliance on human-annotated reasoning trajectories. The model achieved an AIME 2024 pass@1 accuracy of 77.9% with R1-Zero, and the multi-stage DeepSeek-R1 surpassed state-of-the-art models on numerous math, coding, and STEM benchmarks while exhibiting emergent self-reflection and dynamic strategy adaptation.
DeepSeek-AI 开发了 DeepSeek-R1,该模型证明了复杂的推理能力可以通过纯基于结果的强化学习涌现,而无需依赖人工标注的推理轨迹。R1-Zero 版本在 AIME 2024 测试中即达到了 77.9% 的 pass@1 准确率;而经过多阶段优化的 DeepSeek-R1 更是在众多数学、编程和理工科(STEM)基准测试中超越了现有的最先进模型,同时展现出了涌现的自我反思与动态策略调整能力。
注释与术语说明
- 纯基于结果的强化学习:指仅根据最终输出的结果(正确或错误)来给予奖励或惩罚,而不需要对中间的思考过程进行人为拆解或引导。
- 人工标注的推理轨迹:指人工撰写的“思维链”或详细的解题步骤,许多传统模型依赖这些数据来学习推理,而 DeepSeek-R1 旨在摆脱这种依赖。
- Pass@1:代码生成和数学推理中的常用指标,指模型生成的第一个答案即为正确答案的概率。
- 涌现:在复杂系统理论中,指整体展现出个体所不具备的新特性。此处指模型在训练过程中自发产生了自我反思等未被显式编程的能力。
- 理工科:Science, Technology, Engineering, and Mathematics,即科学、技术、工程和数学。
Core Research Framework
核心研究框架
The DeepSeek-R1 research introduces a paradigm shift in training reasoning-capable large language models (LLMs). Rather than relying on traditional supervised fine-tuning (SFT) with human-annotated reasoning examples, this work demonstrates that sophisticated reasoning abilities can emerge organically through pure outcome-based reinforcement learning (RL). The research challenges the conventional wisdom that high-quality human demonstrations are essential for teaching complex reasoning, proposing instead that models can discover superior, non-human-like reasoning pathways through self-evolution.
DeepSeek-R1 的研究为训练具备推理能力的大语言模型(LLM)引入了范式转变。该研究不再依赖传统的人工标注推理示例进行监督微调(SFT),而是展示了复杂的推理能力可以通过纯基于结果的强化学习(RL)自然涌现。这一成果挑战了以往认为“高质量的人类演示是教授复杂推理的必要条件”的传统观念,并提出模型完全可以通过自我进化,发现比人类思维方式更优越的、非类人的推理路径。
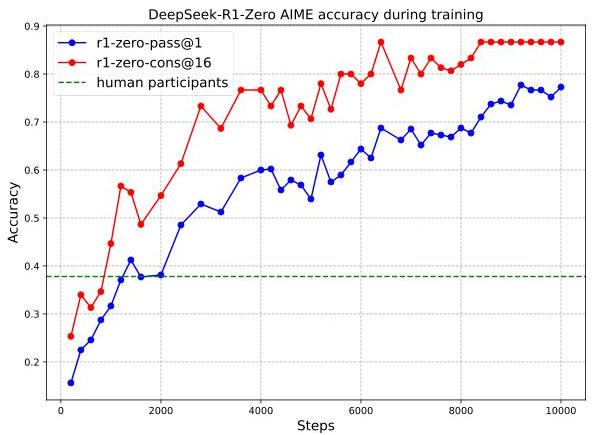
The figure above illustrates the dramatic improvement in DeepSeek-R1-Zero’s performance on the AIME 2024 benchmark during pure RL training. The model’s accuracy increased from 15.6% to 77.9% with pass@1 sampling, and reached 86.7% with self-consistency decoding, significantly surpassing the average human participant performance (39%).
上图展示了 DeepSeek-R1-Zero 在纯 RL 训练期间于 AIME 2024 基准测试中的显著性能提升。在使用 pass@1 采样方法时,模型的准确率从 15.6% 飞跃至 77.9%;而在采用自一致性解码时,准确率更是达到了 86.7%,显著超越了人类参赛者的平均水平(39%)
术语与概念解析
- 范式转变:指在科学研究或技术领域中,基本的假设或理论模式发生了根本性的变化。此处指从依赖人工标注转向依赖强化学习的过程。
- 监督微调:机器学习的一种方法,使用标记好的数据集来预训练后的模型进行调整。
- 自然涌现:指复杂的行为模式并非被显式编程,而是从简单的规则或训练过程中自动产生。此处指推理能力不是被“教”出来的,而是从奖励机制中“长”出来的。
- 非类人的推理路径:指模型解决问题的逻辑步骤与人类通常的思维方式不同,可能更高效或更奇特。
- 自我进化:指模型在训练循环中不断自我迭代、通过自身生成的数据进行改进的过程。
- Pass@1 采样:一种评估指标,指模型一次性生成一个答案,该答案即为正确的概率。这是衡量模型“一次性成功率”的严格标准。
- 自一致性解码:一种解码策略,指让模型针对同一个问题生成多个不同的推理路径和答案,然后通过投票选择出现频率最高的答案。这通常比单次采样能获得更高的准确率。
Methodology and Training Architecture
方法与训练架构
Base Model and Core Algorithm
基础模型与核心算法
DeepSeek-R1 builds upon DeepSeek-V3-Base, a Mixture-of-Experts (MoE) architecture with 671 billion total parameters and 37 billion activated per token. The core training algorithm is Group Relative Policy Optimization (GRPO), a more resource-efficient variant of Proximal Policy Optimization (PPO). GRPO eliminates the need for a separate value model and estimates advantages from grouped rewards, reducing computational overhead while avoiding implicit penalties on response length that might hinder long chain-of-thought development.
DeepSeek-R1 构建于 DeepSeek-V3-Base 之上,这是一个混合专家架构,拥有 6710 亿个总参数,每 token 激活参数量为 370 亿。其核心训练算法是组相对策略优化,这是近端策略优化的一种资源效率更高的变体。GRPO 摒弃了对独立价值模型的需求,通过分组奖励来估计优势函数,不仅降低了计算开销,还避免了对响应长度的隐性惩罚——这种惩罚往往可能会阻碍长思维链的发展。
Multi-Stage Training Framework
多阶段训练框架
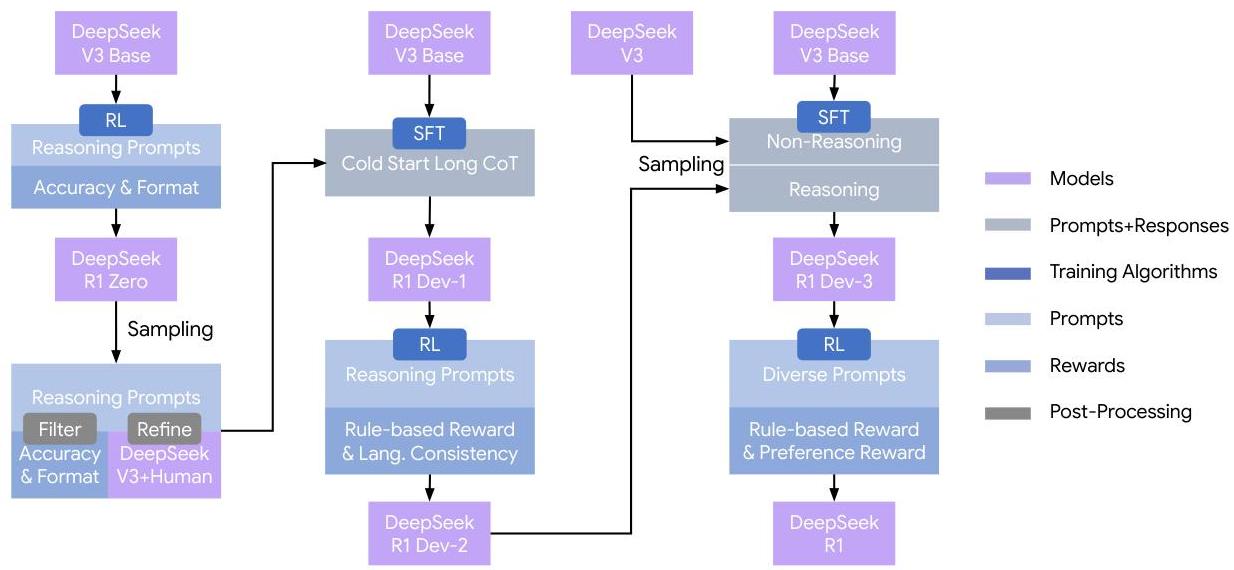
The research employs two distinct approaches: DeepSeek-R1-Zero for pure RL reasoning development, and DeepSeek-R1 for practical deployment. DeepSeek-R1-Zero applies RL directly to the base model without any prior SFT, using:
本研究采用了两种截然不同的方法:用于纯强化学习推理能力开发的 DeepSeek-R1-Zero,以及面向实际部署的 DeepSeek-R1。 DeepSeek-R1-Zero 直接将强化学习应用于基础模型,无需任何先前的监督微调(SFT),具体采用了:
- Rule-based rewards: Binary accuracy rewards (correct/incorrect final answers) and format rewards (proper reasoning structure using
<think>...</think><answer>...</answer>tags) - Extensive exploration: High sampling temperature (1.0) and very long response lengths (up to 65,536 tokens)
- Objective feedback: Compiler-based evaluation for coding problems and answer format verification for mathematics
- 基于规则的奖励:二元准确性奖励(针对最终答案的正确与否)以及格式奖励(针对使用 标签构建的规范推理结构)
- 广泛的探索:高采样温度(1.0)以及极长的响应长度(最长可达 65,536 个 token)
- 客观反馈:针对编程问题的基于编译器的评估,以及针对数学问题的答案格式验证
DeepSeek-R1 implements a sophisticated multi-stage pipeline:
This framework addresses practical limitations of R1-Zero (poor readability, language mixing) while preserving reasoning capabilities. The process incorporates both rule-based and model-based rewards, including helpful and safety reward models trained on human preference data.
该框架在保留推理能力的同时,解决了 R1-Zero 在实际应用中的局限性(如可读性差、语言混杂等问题)。该流程融合了基于规则和基于模型的奖励机制,包括基于人类偏好数据训练的有用性和安全性奖励模型。
术语与技术解析
- 混合专家架构:一种神经网络架构,它将模型划分为多个专家子模型,但对于每个输入,只激活其中的一部分专家(即“激活”的参数),从而在保持高性能的同时提高计算效率。
- 组相对策略优化:这是论文中提出的核心改进算法。传统的 PPO 需要训练一个庞大的价值模型来评判状态好坏,计算量大。GRPO 则通过从一组采样的响应中计算相对优势(基准线),省去了价值模型,大幅降低了显存和计算消耗。
- 价值模型:强化学习中的一个组件,用于预测当前状态的未来预期回报。GRPO 的创新点在于去除了这一组件。
- 冷启动 SFT:指在没有强化学习之前,先用少量高质量数据对模型进行微调,赋予模型基本的推理格式和模式,以便后续强化学习能更有效地进行。
- 拒绝采样:一种数据收集策略,模型生成多个回答,通过评估器筛选出通过(即被接受)的回答,这些回答被用于后续的监督微调。
- 思维链:指模型在给出最终答案之前,生成一系列中间推理步骤的过程。
- 语言混杂:指模型在生成文本时混合使用多种语言(如中英文夹杂)的现象,这通常在缺乏充分监督的情况下出现。DeepSeek-R1 通过引入二次 SFT 解决了这个问题。
Emergent Reasoning Behaviors
涌现的推理行为
Organic Development of Complex Reasoning Patterns
复杂推理模式的自然演进
DeepSeek-R1-Zero demonstrates remarkable emergent behaviors during training. The model naturally develops sophisticated reasoning strategies including:
- Self-reflection: Dramatic increases in reflective language use, with words like “wait,” “evaluate,” and “retry” appearing 5-7 times more frequently
- Verification: Active attempts to check and validate reasoning steps
- Dynamic strategy adaptation: Evidence of “aha moments” where the model suddenly shifts its approach to problem-solving
- 自我反思:反思性语言的使用急剧增加,诸如“wait”(稍等)、“evaluate”(评估)和“retry”(重试)等词汇的出现频率提升了 5 到 7 倍。
- 验证检查:主动尝试检查并验证推理步骤。
- 动态策略适应:出现了“顿悟时刻”的迹象,即模型会突然改变其解决问题的方法。
术语与概念解析
- 涌现行为:在复杂系统理论中,指简单规则或底层机制在互动中产生出的复杂、不可预测的高级行为。在这里特指模型并没有被显式编程“去反思”,但在强化学习的奖励驱动下,自己学会了反思。
- 自然演进:强调这些能力是通过训练过程自动生成的,而非人类工程师手工编写或通过大量人工标注数据硬性灌输的。
- 顿悟时刻:心理学词汇,指突然理解问题或找到解决方案的瞬间。在 AI 推测中,指模型在生成过程中突然切换解题思路,并在后续的回答中展现出更正确或高效的逻辑路径。
- 反思性语言:指模型在输出推理链时,使用了体现自我监控、自我纠错倾向的词汇。DeepSeek-R1-Zero 因为没有经过 SFT 压制,反而保留了这种原始的“思考痕迹”。
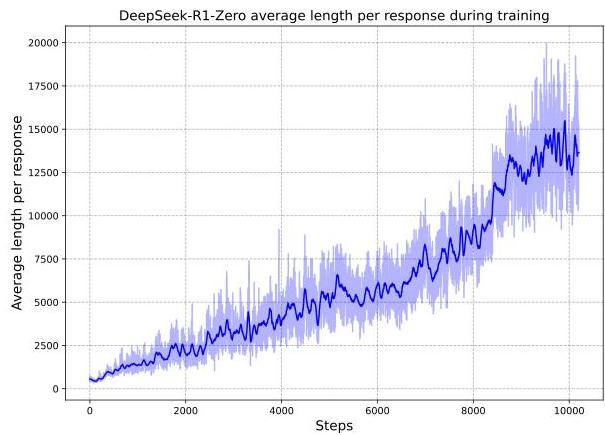
The figure shows how DeepSeek-R1-Zero naturally learns to generate longer responses (“thinking time”) as training progresses, with average response length increasing from under 1,000 to over 14,000 tokens, indicating the development of more elaborate reasoning processes.
上图展示了随着训练的推进,DeepSeek-R1-Zero 如何自然地学会生成更长的响应(即“思考时间”),其平均响应长度从不足 1,000 个 token 增加到了超过 14,000 个 token,这标志着更精细的推理过程正在形成。
术语与概念解析
- 思考时间:此处是一个形象的比喻,指模型在给出最终答案前生成的推理链的长度。就像人类在解决复杂问题时需要更多时间思考一样,模型通过增加生成 token 的数量,实际上是在进行更多的“思维步骤”计算。数据表明,模型自发地意识到需要更多计算步骤来解决难题。
- Token:大语言模型处理文本的最小单位。在这里,token 数量直接对应模型消耗的计算量和推理的深度。
Adaptive Compute Allocation
自适应计算分配
DeepSeek-R1 demonstrates sophisticated test-time compute scaling, dynamically adjusting reasoning complexity based on problem difficulty. For simple mathematical problems, it uses fewer than 7,000 thinking tokens, while the most challenging problems trigger over 18,000 tokens of internal reasoning.
DeepSeek-R1 展现了精密的推理时计算扩展能力,能够根据问题难度动态调整推理的复杂度。对于简单的数学问题,它使用少于 7,000 个“思考 token”;而对于最具挑战性的问题,则会触发超过 18,000 个 token 的内部推理。
Performance Results and Benchmarks
性能结果与基准测试
Mathematical Reasoning Excellence
数学推理的卓越表现
DeepSeek-R1 achieves exceptional performance across mathematical benchmarks:
- AIME 2024: 79.8% pass@1 accuracy
- MATH-500: 97.3% accuracy
- Codeforces: 96.3 percentile performance
These results often match or exceed state-of-the-art models like OpenAI-o1, demonstrating the effectiveness of the RL-based reasoning development approach.
这些结果往往能够匹敌甚至超越 OpenAI-o1 等最先进的模型,有力地证明了这种基于强化学习的推理开发方法的有效性。
Competitive Performance Across Domains
各领域的竞争力表现
The comprehensive training framework enables strong performance beyond mathematics:
综合训练框架带来的广泛优势
- Coding: 65.9% on LiveCodeBench
- Scientific Reasoning: 71.5% on GPQA Diamond
- General Knowledge: 84.0% on MMLU-Pro
- 编程能力:在 LiveCodeBench 上取得 65.9% 的成绩
- 科学推理:在 GPQA Diamond 上达到 71.5%
- 通用知识:在 MMLU-Pro 上达到 84.0%
The model particularly excels in STEM categories, where verifiable reasoning tasks align well with the RL training paradigm.
该模型在 STEM(科学、技术、工程和数学)领域表现尤为出色,因为这些领域的任务通常具备可验证性,这与强化学习(RL)的训练范式高度契合。
术语与概念解析
- LiveCodeBench:一个用于评估大语言模型代码生成能力的基准测试平台。它通常使用最新的、真实世界的编程任务,而非过时的静态题目,能有效测试模型的实际编程能力和泛化性。
- GPQA Diamond:即“研究生级谷歌-proof 问答”数据集的 Diamond 子集。这是一个极具挑战性的科学基准,包含物理、生物和化学等领域的专家级难题。其题目非常困难,甚至非该领域的专家博士生也难以回答高分。
- MMLU-Pro:MMLU(Massive Multitask Language Understanding)的升级版。相比原版,它在题目设计上增加了难度和质量,选项更多,且排除了简单记忆就能回答的问题,更侧重考察模型的推理能力和知识深度。
- 可验证的推理任务:指那些存在客观、明确标准来判断答案正确与否的任务(如数学题答案唯一、代码运行报错或通过)。这对强化学习至关重要,因为 RL 需要清晰的奖励信号来告诉模型它的思考方向是否正确。STEM 领域正好提供了这种明确的反馈机制。
- STEM:Science, Technology, Engineering, Mathematics 的缩写,指科学、技术、工程和数学四大领域。
Knowledge Distillation and Democratization
知识蒸馏与民主化
Effective Transfer to Smaller Models
向小模型的有效迁移
The research demonstrates successful knowledge distillation from DeepSeek-R1 to smaller models across different architectures:
研究表明,DeepSeek-R1 已经成功地将知识迁移到了不同架构的较小模型中:
Notably, a 1.5B parameter Qwen model distilled from DeepSeek-R1 surpasses many larger models on mathematical benchmarks, highlighting the efficiency of this transfer approach. Experiments show that distillation consistently outperforms direct RL training on smaller base models, making advanced reasoning capabilities accessible with fewer computational resources.
值得注意的是,一个由 DeepSeek-R1 蒸馏而来的 1.5B(15亿)参数 Qwen 模型,在数学基准测试中超越了多个参数量更大的模型,这突显了这种迁移方法的高效性。实验表明,在较小的基座模型上,蒸馏的效果始终优于直接进行强化学习训练,这意味着只需更少的计算资源,就能获得先进的推理能力。
术语与概念解析
- 知识蒸馏:一种模型压缩技术。旨在将一个庞大、复杂的“教师模型”(这里是 DeepSeek-R1)学到的知识迁移到一个轻量级的“学生模型”(如 Qwen)中,使学生模型在保持较小体积的同时,能获得接近甚至媲美大模型的性能。
- 民主化:在人工智能领域,指通过降低技术门槛和成本(如计算资源、资金),让更多个人、小企业或开发者能够使用先进技术,而不仅仅局限于科技巨头。在此处,指通过蒸馏技术,让普通硬件也能运行高性能推理模型。
- 基座模型:指未经大规模指令微调或润色、处于基础阶段的模型。实验表明直接在这些小基座模型上做强化学习效果不佳,不如先用大模型蒸馏。
- Qwen / LLaMA:分别代表通义千问(阿里巴巴)和 LLaMA(Meta)系列的开源模型架构,说明该方法具有良好的跨架构通用性。
- 1.5B:指 1.5 Billion(15亿)参数。在现代大模型动辄万亿参数的背景下,15亿参数的模型非常轻量,可以在普通消费级显卡甚至笔记本电脑上运行。
Technical Infrastructure and Scalability
技术基础设施与可扩展性
Reinforcement Learning System Design
强化学习系统设计
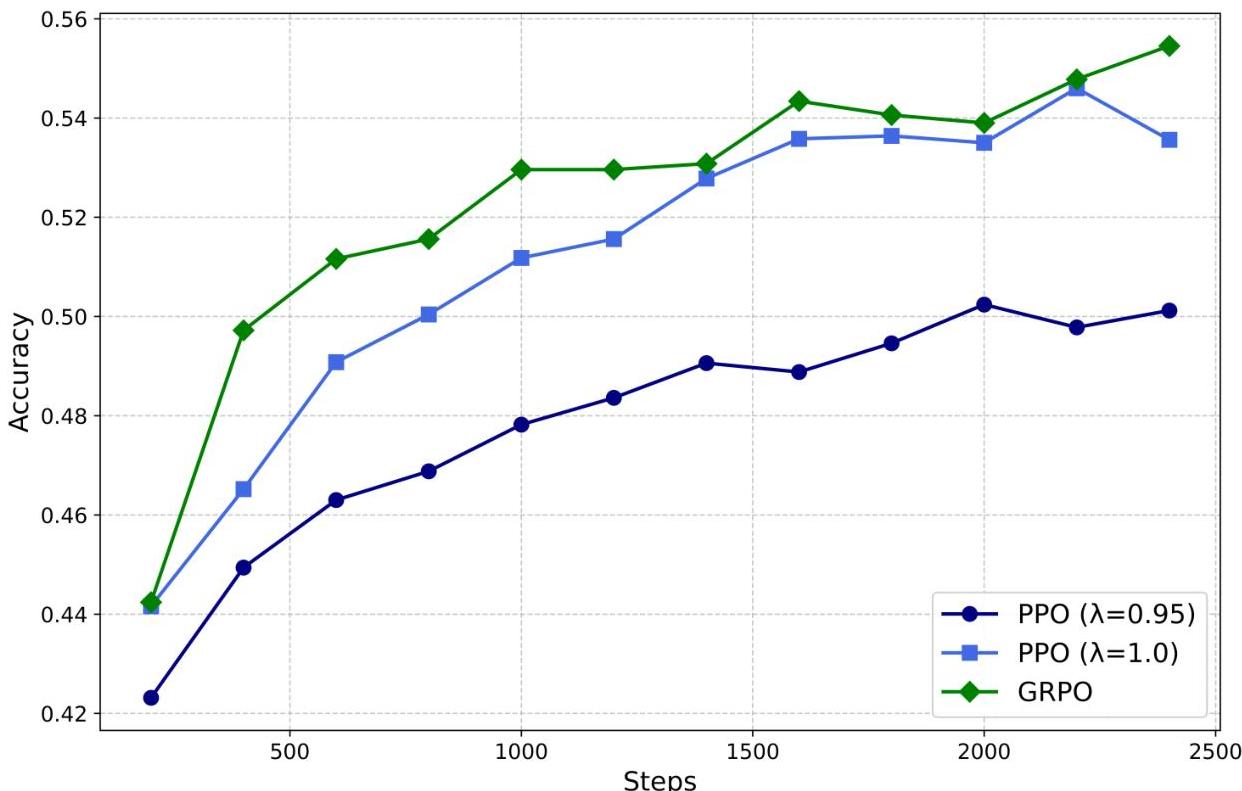
The research employs a sophisticated RL infrastructure designed for large-scale training. GRPO demonstrates superior efficiency compared to traditional PPO, achieving faster convergence and more stable training dynamics. The system architecture includes:
该研究采用了专门为大规模训练设计的精密强化学习(RL)基础设施。GRPO(Group Relative Policy Optimization)展现了优于传统 PPO 的效率,实现了更快的收敛速度和更稳定的训练动态。其系统架构包括:
- Optimized memory management: VRAM-efficient model handling for massive parameter counts
- Parallel evaluation: Overlapped execution of code evaluation and answer matching
- Scalable reward computation: Rule-based systems for objective feedback at scale
- 优化的内存管理:针对海量参数的高效 VRAM(显存)模型处理机制
- 并行评估:代码评估与答案匹配的重叠执行(Overlapped execution)
- 可扩展的奖励计算:用于大规模客观反馈的基于规则的系统
Limitations and Future Directions
局限性与未来方向
Current Constraints
当前局限性
The research identifies several limitations:
- Verifiable task dependency: Current RL approach works best for problems with objective evaluation criteria
- Language consistency challenges: Multilingual models may exhibit language mixing in reasoning processes
- Structured output limitations: Less effective for tasks requiring specific formatting or tool usage
研究指出了以下几个方面的局限性:
- 对可验证任务的依赖:当前的强化学习方法在具有客观评估标准的问题上效果最佳
- 语言一致性挑战:多语言模型在推理过程中可能会出现语言混杂现象
- 结构化输出局限:在需要特定格式或工具使用的任务上效果欠佳
Research Trajectory
研究轨迹
The paper outlines clear future directions:
- Robust reward models: Development of reliable evaluation systems for subjective tasks
- Tool integration: Enhancing reasoning with external computational resources
- Token efficiency: Optimizing the length-performance trade-off in reasoning processes
- Reward hacking mitigation: Addressing potential gaming of evaluation metrics
论文概述了明确的未来方向:
- 鲁棒的奖励模型:针对主观任务开发可靠的评估系统
- 工具集成:利用外部计算资源增强推理能力
- Token 效率:优化推理过程中的长度与性能权衡
- 缓解奖励黑客行为:解决针对评估指标的潜在博弈(Gaming)问题
Significance and Impact
意义与影响
DeepSeek-R1 represents a fundamental advancement in reasoning-capable AI systems. By demonstrating that sophisticated reasoning can emerge through self-evolution rather than human imitation, the research opens new possibilities for autonomous AI development. The work’s emphasis on outcome-based learning over process supervision suggests that AI systems can discover reasoning strategies that potentially exceed human cognitive patterns.
The successful knowledge distillation component addresses practical deployment concerns, making advanced reasoning capabilities accessible across different computational budgets. This democratization aspect, combined with the open-source release of model weights, positions the research to have broad impact across the AI research community.
The research contributes to the growing understanding of how to scale inference-time computation effectively, showing that RL can teach models to automatically allocate more reasoning resources to challenging problems. This adaptive approach to computational resource allocation represents an important step toward more efficient and capable AI systems.
DeepSeek-R1 代表了具备推理能力的 AI 系统的一项根本性进展。通过证明复杂的推理可以通过自我进化而非单纯模仿人类产生,该研究为自主 AI 的开发开辟了新的可能性。这项工作强调基于结果的学习而非过程监督,这表明 AI 系统可能会发现某种潜在超越人类认知模式的推理策略。
成功的知识蒸馏组件解决了实际的部署顾虑,使得在不同算力预算下都能获得先进的推理能力。这种民主化特性,加上模型权重的开源发布,使得这项研究有望在整个 AI 研究社区产生广泛影响。
该研究有助于我们深入理解如何有效地扩展推理时计算,证明强化学习可以教会模型自动为更具挑战性的问题分配更多的推理资源。这种计算资源分配的自适应方法,是迈向更高效、更强大 AI 系统的重要一步。
术语与概念解析
- GRPO (Group Relative Policy Optimization):一种新型的强化学习算法。与传统的 PPO(Proximal Policy Optimization,近端策略优化)相比,GRPO 通过组采样的方式计算优势函数,省略了需要大量显存的批评模型(Critic Model),从而在大幅降低显存占用的同时,保持了甚至超越 PPO 的性能。这使得在大规模模型上进行强化学习训练变得更加可行。
- VRAM-efficient:指对显存的使用进行了深度优化。在大模型训练中,显存通常是主要瓶颈,高效的内存管理意味着可以在同样的硬件上训练更大的模型或使用更大的批次。
- 重叠执行:指在计算机系统中,将不同的计算任务在时间上重叠进行(例如在进行 CPU 计算的同时进行 GPU 数据传输),以减少总体的等待时间,提高系统吞吐量。
- 奖励黑客:强化学习中的一个常见问题,指智能体找到一种“作弊”的方法来获得高奖励分数,而不是真正完成预期的任务。例如,在游戏中,智能体可能发现只要在这个角落反复震动就能得分,而不是通过过关。解决这一问题对于训练出真正有能力的模型至关重要。
- 推理时计算:指模型在实际运行生成答案阶段所消耗的计算资源。DeepSeek-R1 的核心突破在于证明了可以通过 RL 训练,让模型学会在推理时根据难度“自主决定”花多少算力去思考,这改变了以往模型推理算力固定的模式。
Relevant Citations
Chain-of-thought prompting elicits reasoning in large language models
This is the seminal paper that introduced Chain-of-Thought (CoT) prompting, a concept central to the DeepSeek-R1 paper. The main paper’s contribution is to show that these complex reasoning chains can be incentivized through reinforcement learning, building directly on the foundation established by this work.
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022b. URL http://papers.nips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html.
Training language models to follow instructions with human feedback
This paper establishes the widely adopted post-training paradigm of Supervised Fine-Tuning (SFT) followed by Reinforcement Learning from Human Feedback (RLHF). The DeepSeek-R1 paper’s methodology, particularly the choice to bypass the SFT stage, is a direct response to this conventional approach, making this citation crucial for contextualizing the novelty of their work.
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.
Proximal policy optimization algorithms
This paper introduces Proximal Policy Optimization (PPO), the standard algorithm for reinforcement learning in large language models. The DeepSeek-R1 paper utilizes a novel algorithm, Group Relative Policy Optimization (GRPO), which it explicitly defines and compares as a simplification of PPO, making this a foundational technical reference.
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
Deepseekmath: Pushing the limits of mathematical reasoning in open language models
This citation is of paramount importance as it introduces Group Relative Policy Optimization (GRPO), the specific reinforcement learning algorithm that forms the core of the DeepSeek-R1 training framework. The main paper directly adopts and builds upon the GRPO method proposed in this work to achieve its results.
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. Li, Y. Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.